
ЙЋЫОДњТыЃК688787 ЙЋЫОМђГЦЃККЃЬьШ№Щљ
ББОЉКЃЬьШ№ЩљПЦММЙЩЗнгаЯоЙЋЫО
2021ФъФъЖШБЈИцеЊвЊ
ЕквЛНк живЊЬсЪО
1 БОФъЖШБЈИцеЊвЊРДздФъЖШБЈИцШЋЮФЃЌЮЊШЋУцСЫНтБОЙЋЫОЕФОгЊГЩЙћЁЂВЦЮёзДПіМАЮДРДЗЂеЙЙцЛЎЃЌЭЖзЪепгІЕБЕНwww.sse.com.cnЭјеОзаЯИдФЖСФъЖШБЈИцШЋЮФЁЃ2 жиДѓЗчЯеЬсЪОЙЋЫОвбдкБОБЈИцжаЯъЯИУшЪіПЩФмДцдкЕФЗчЯеЃЌОДЧыВщдФЁАЕкШ§НкЙмРэВуЬжТлгыЗжЮіЁБЃЈжЎЫФЃЉЁАЗчЯевђЫиЁБВПЗжЃЌЧыЭЖзЪепзЂвтЭЖзЪЗчЯеЁЃ3 БОЙЋЫОЖЪТЛсЁЂМрЪТЛсМАЖЪТЁЂМрЪТЁЂИпМЖЙмРэШЫдББЃжЄФъЖШБЈИцФкШнЕФецЪЕадЁЂзМШЗадЁЂЭъећадЃЌВЛДцдкащМйМЧдиЁЂЮѓЕМадГТЪіЛђжиДѓвХТЉЃЌВЂГаЕЃИіБ№КЭСЌДјЕФЗЈТЩд№ШЮЁЃ
4 ЙЋЫОШЋЬхЖЪТГіЯЏЖЪТЛсЛсвщЁЃ
5 аХгРжаКЭЛсМЦЪІЪТЮёЫљЃЈЬиЪтЦеЭЈКЯЛяЃЉЮЊБОЙЋЫОГіОпСЫБъзМЮоБЃСєвтМћЕФЩѓМЦБЈИцЁЃ
6 ЙЋЫОЩЯЪаЪБЮДгЏРћЧвЩаЮДЪЕЯжгЏРћ
ЁѕЪЧ ЁЬЗё
7 ЖЪТЛсОівщЭЈЙ§ЕФБОБЈИцЦкРћШѓЗжХфдЄАИЛђЙЋЛ§Н№зЊдіЙЩБОдЄАИЙЋЫОФтвдЪЕЪЉШЈвцЗжХЩЙЩШЈЕЧМЧШеЕЧМЧЕФзмЙЩБОЮЊЛљЪ§ЗжХфРћШѓЃЌЯђШЋЬхЙЩЖЋУП10ЙЩХЩЗЂЯжН№КьРћ2.50дЊЃЈКЌЫАЃЉЁЃНижС2021Фъ12дТ31ШеЃЌЙЋЫОзмЙЩБО42,800,000ЙЩ,вдДЫКЯМЦФтХЩЗЂЯжН№КьРћ10,700,000.00дЊ(КЌЫА)ЁЃБОФъЖШЯжН№ЗжКьзмЖюеМКЯВЂБЈБэЪЕЯжЙщЪєгкЩЯЪаЙЋЫОЙЩЖЋОЛРћШѓЕФ
33.85%ЃЛЙЋЫОБОДЮВЛНјаазЪБОЙЋЛ§зЊдіЙЩБОЃЌВЛЫЭКьЙЩЁЃ
ЩЯЪіРћШѓЗжХфЗНАИвбОЙЋЫОЕкЖўНьЖЪТЛсЕкЦпДЮЛсвщЩѓвщЭЈЙ§ЃЌЩаашЬсНЛЙЋЫО2021ФъФъЖШЙЩЖЋДѓЛсЩѓвщЁЃ8 ЪЧЗёДцдкЙЋЫОжЮРэЬиЪтАВХХЕШживЊЪТЯю
ЁѕЪЪгУ ЁЬВЛЪЪгУ
ЕкЖўНк ЙЋЫОЛљБОЧщПі1 ЙЋЫОМђНщЙЋЫОЙЩЦБМђПі
ЁЬЪЪгУ ЁѕВЛЪЪгУ
| ЙЋЫОЙЩЦБМђПі | ||||
| ЙЩЦБжжРр | ЙЩЦБЩЯЪаНЛвзЫљМААхПщ | ЙЩЦБМђГЦ | ЙЩЦБДњТы | БфИќЧАЙЩЦБМђГЦ |
| ШЫУёБвЦеЭЈЙЩЃЈAЙЩЃЉ | ЩЯКЃжЄШЏНЛвзЫљПЦДДАх | КЃЬьШ№Щљ | 688787 | ВЛЪЪгУ |
ЙЋЫОДцЭаЦОжЄМђПі
ЁѕЪЪгУ ЁЬВЛЪЪгУ
СЊЯЕШЫКЭСЊЯЕЗНЪН
| СЊЯЕШЫКЭСЊЯЕЗНЪН | ЖЪТЛсУиЪщЃЈаХЯЂХћТЖОГФкДњБэЃЉ | жЄШЏЪТЮёДњБэ |
| аеУћ | ТРЫМвЃ | еХем |
| АьЙЋЕижЗ | ББОЉЪаКЃЕэЧјГЩИЎТЗ28КХ4-801 | ББОЉЪаКЃЕэЧјГЩИЎТЗ28КХ4-801 |
| ЕчЛА | 010-62660772 | 010-62660772 |
| ЕчзгаХЯф | ir@speechocean.com | ir@speechocean.com |
2 БЈИцЦкЙЋЫОжївЊвЕЮёМђНщ
(вЛ) жївЊвЕЮёЁЂжївЊВњЦЗЛђЗўЮёЧщПі
1) жївЊвЕЮёЧщПі
ЙЋЫОжївЊДгЪТAIбЕСЗЪ§ОнЕФбаЗЂЩшМЦЁЂЩњВњМАЯњЪлвЕЮёЁЃЙЋЫОЭЈЙ§ЩшМЦЪ§ОнМЏНсЙЙЁЂзщжЏЪ§ОнВЩМЏЁЂЖдШЁЕУЕФдСЯЪ§ОнНјааМгЙЄЃЌзюжеаЮГЩПЩЙЉAIЫуЗЈФЃаЭбЕСЗЪЙгУЕФзЈвЕЪ§ОнМЏЃЌЭЈЙ§ШэМўаЮЪНЯђПЭЛЇНЛИЖЁЃ
ЫуЗЈЁЂЫуСІЁЂЪ§ОнЪЧШЫЙЄжЧФмММЪѕЗЂеЙЕФШ§ДѓвЊЫиЃЌЦфжабЕСЗЪ§ОнЪЧЫуЗЈЗЂеЙКЭбнНјЕФЁАШМСЯЁБЁЃдкЕБЧАММЪѕЗЂеЙНјГЬжаЃЌЩюЖШбЇЯАЫуЗЈЪЧЭЦЖЏШЫЙЄжЧФмММЪѕШЁЕУЭЛЦЦадЗЂеЙЕФЙиМќММЪѕРэТлЃЌЖјДѓСПбЕСЗЪ§ОнЕФбЕСЗжЇГХдђЪЧЩюЖШбЇЯАЫуЗЈЪЕЯжЕФЛљДЁЁЃЩюЖШбЇЯАЗжЮЊЁАбЕСЗЁБКЭЁАЭЦЖЯЁБСНИіЛЗНкЃКбЕСЗашвЊКЃСПЪ§ОнЪфШыЃЌбЕСЗГівЛИіИДдгЕФЩюЖШЩёОЭјТчФЃаЭЃЛЭЦЖЯжИРћгУбЕСЗКУЕФФЃаЭЃЌШЅЁАЭЦЖЯЁБЯжЪЕГЁОАжаЕФД§ХаЖЯЪ§ОнЃЌВЂЕУГіИїжжНсТлЁЃбЕСЗЪ§ОндНЖрЁЂдНЭъећЁЂжЪСПдНИпЃЌФЃаЭЭЦЖЯЕФНсТлдНПЩППЁЃвђДЫЃЌвЊЪЙЫуЗЈФЃаЭЪЕЯжДгММЪѕРэТлЕНгІгУЪЕМљЕФТфЕиЙ§ГЬЃЌОЭашвЊЬсЙЉДѓСПЕФбЕСЗЪ§ОнЃЌЖдЫуЗЈФЃаЭМгвдбЕСЗЁЃЭЈГЃЃЌДгздШЛЪ§ОндДМђЕЅЪеМЏШЁЕУЕФдСЯЪ§ОнВЂВЛФмжБНггУгкЩюЖШбЇЯАЫуЗЈЕФбЕСЗЃЌБиаыОЙ§зЈвЕЛЏЕФВЩМЏЁЂМгЙЄДІРэЃЌаЮГЩЯргІЕФЙЄГЬЛЏЪ§ОнМЏКѓВХФмЙЉЩюЖШбЇЯАЫуЗЈЕШЫуЗЈЁЂФЃаЭбЕСЗЪЙгУЁЃ
ЯАНќЦНзмЪщМЧдјЧПЕїЃКЁАвЊЙЙНЈвдЪ§ОнЮЊЙиМќвЊЫиЕФЪ§зжОМУЁЃЁБЃЌЁЖжаЙВжабыЙњЮёдКЙигкЙЙНЈИќМгЭъЩЦЕФвЊЫиЪаГЁЛЏХфжУЬхжЦЛњжЦЕФвтМћЁЗЖдМгПьХрг§Ъ§ОнвЊЫиЪаГЁвВзїГіСЫВПЪ№ЁЃЪ§ОнЪЧаТЕФЩњВњвЊЫиЃЌЪЧЛљДЁадзЪдДКЭеНТдадзЪдДЁЃ2021Фъ3дТЃЌНЈЩшШЫЙЄжЧФмбЕСЗЪ§ОнМЏЁЂЗЂеЙШЋЪ§ОнВњвЕСДвбБЛе§ЪНФЩШыЙњМвЪЎЫФЮхЙцЛЎЁЃбЕСЗЪ§ОнвбОГЩЮЊЙњМвжиЪгЁЂжЇГжКЭЭЦЖЏЕФШЫЙЄжЧФмВњвЕЗЂеЙЫљБиашЕФЙиМќВњЦЗЁЂЙиМќВФСЯЁЃ
зд2005ФъГЩСЂвдРДЃЌЙЋЫОЪМжежТСІгкЮЊAIВњвЕСДЩЯЕФИїРрЛњЙЙЬсЙЉЫуЗЈФЃаЭПЊЗЂбЕСЗЫљашЕФзЈвЕЪ§ОнМЏЁЃОЙ§ЖрФъЗЂеЙЃЌЙЋЫОвбГЩЮЊШЫЙЄжЧФмЛљДЁЪ§ОнЗўЮёСьгђОпгаНЯЧПЙњМЪОКељСІЕФЙњФкЭЗВПЦѓвЕЃЌВЂЪЕЯжСЫБъзМЛЏВњЦЗЁЂЖЈжЦЛЏЗўЮёЁЂЯрЙигІгУЗўЮёШЋИВИЧЁЃЙЋЫОЫљЬсЙЉЕФбЕСЗЪ§ОнКИЧжЧФмгявєЃЈгявєЪЖБ№ЁЂгявєКЯГЩЕШЃЉЁЂМЦЫуЛњЪгОѕЁЂздШЛгябдЕШЖрИіКЫаФСьгђЃЌШЋУцЗўЮёгкШЫЛњНЛЛЅЁЂжЧФмМвОгЁЂжЧФмМнЪЛЁЂжЧЛлН№ШкЁЂжЧФмАВЗРЕШЖржжДДаТгІгУГЁОАЁЃ
ЙЋЫОЕФВњЦЗКЭЗўЮёвбЛёЕУАЂРяАЭАЭЁЂЬкбЖЁЂАйЖШЁЂПЦДѓбЖЗЩЁЂКЃПЕЭўЪгЁЂзжНкЬјЖЏЁЂЮЂШэЁЂбЧТэбЗЁЂШ§аЧЁЂжаЙњПЦбЇдКЁЂЧхЛЊДѓбЇЕШЙњФкЭтПЭЛЇЕФШЯПЩЃЌгІгУгкЦфбаЗЂЕФИіШЫжњЪжЁЂжЧФмвєЯфЁЂгявєЕМКНЁЂЫбЫїЗўЮёЁЂЖЬЪгЦЕЁЂащФтШЫЁЂжЧФмМнЪЛЁЂЛњЦїЗвыЕШЖржжВњЦЗЯрЙиЕФЫуЗЈФЃаЭбЕСЗЙ§ГЬжаЁЃФПЧАЙЋЫОПЭЛЇРлМЦЪ§СП695МвЃЌИВИЧСЫПЦММЛЅСЊЭјЁЂЩчНЛЁЂIoTЁЂжЧФмМнЪЛЁЂжЧЛлН№ШкЕШСьгђЕФжїСїЦѓвЕЃЌНЬг§ПЦбаЛњЙЙвдМАВПЗжеўЦѓЛњЙЙЁЃ
ЭМЃКЙЋЫОВњЦЗЗўЮёОиеѓЪОвт
2) жївЊВњЦЗМАЗўЮёЧщПі
2.1жївЊВњЦЗМАЗўЮёАДвЕЮёРраЭЗжРр
ЙЋЫОбаЗЂЁЂЩњВњЕФбЕСЗЪ§ОнИВИЧСЫжЧФмгявєЁЂМЦЫуЛњЪгОѕМАздШЛгябдДІРэШ§ДѓAIКЫаФСьгђЃЌЙуЗКгІгУгкЫуЗЈФЃаЭЕФПЊЗЂЁЂбЕСЗЁЂгХЛЏЁЂгІгУГЁОАЭиеЙЕШЛЗНкЁЃДЫЭтЃЌЙЋЫОЛЙЬсЙЉгыбЕСЗЪ§ОнЯрЙиЕФгІгУЗўЮёЁЃ
ЃЈ1ЃЉжЧФмгявє
ШЫЙЄжЧФмдкгявєСьгђЕФгІгУММЪѕжївЊАќРЈгявєЪЖБ№ЁЂгявєКЯГЩЕШЁЃ
гявєЪЖБ№ЃЈAutomatic Speech RecognitionЃЌASRЃЉЪЧШУЛњЦїФмЙЛЁАЬ§ЖЎЁБШЫРргявєЕФММЪѕЃЌЫќФмЪЙЛњЦїздЖЏНЋгявєаХКХзЊЛЛЮЊЖдгІЕФЮФБОаХЯЂЁЃ
гявєКЯГЩЃЈText to SpeechЃЌTTSЃЉЪЧШУЛњЦїФмЙЛЁАЫЕГіЁБШЫРргявєЕФММЪѕЃЌЫќЪЙЛњЦїФмНЋЮФзжаХЯЂзЊЛЏЮЊСїГЉЕФгявєЁАРЪЖСЁБГіРДЃЌЯрЕБгкИјЛњЦїАВЩЯСЫШЫЙЄзьАЭЁЃ
вдШеГЃЩњЛюжаЕФЧщОАЮЊР§ЃЌгявєЪфШыЗЈЁЂМДЪБЭЈбЖШэМўдЫгУСЫгявєЪЖБ№ММЪѕНЋгУЛЇЪфШыЕФгявєЪЕЪБзЊЛЛЮЊЮФзжЃЌЪЕЯжСЫШэМўЁАЬ§ЖЎЁБгявєВЂЁАЬ§аДЁБГіЮФзжЕФаЇЙћЃЛЖјЕиЭМЁЂЕМКНШэМўдђдЫгУгявєКЯГЩММЪѕЃЌЪЕЯжСЫШэМўЁАЗЂЩљЫЕЛАЁБЕФаЇЙћЃЌЮЊгУЛЇЬсЙЉМДЪБгявєЕМКНЁЃ
ЙЋЫОЭЈЙ§ЩшМЦЃЈЩшМЦбЕСЗЪ§ОнМЏНсЙЙЁЂЙЉЗЂвєШЫРЪЖСТМжЦЕФгяСЯЮФБОЛђЖдЛАГЁОАЁЂЗЂвєШЫЗжВМЁЂТМвєЩшБИГЁОАЕШЃЉЁЂВЩМЏЃЈЖЈвхКЯЪЪЕФЗЂвєШЫЁЂбЁШЁТМвєЩшБИМАШэМўЁЂзщжЏЗЂвєШЫРЪЖСТМжЦвєЦЕЃЉЁЂМгЙЄЃЈЖдвєЦЕЮФМўНјааЧаЗжЁЂБъзЂИїРрЩљвєЬиеїЃЌаЮГЩДјЪБМфДСКЭЬиеїБъЧЉЕФЮФБОКЭБъзЂЮФМўЕШЃЉЁЂжЪМьЃЈЖдЪ§ОнМЏНјаажЪСПМьВтЃЌШчвєзжвЛжТадЁЂБъзЂзМШЗТЪМьВщЕШЃЉЕШбЕСЗЪ§ОнМЏЩњВњЛЗНкЃЛЛђепеыЖдПЭЛЇЬсЙЉЕФдСЯвєЦЕЮФМўжДааМгЙЄЁЂжЪМьЙЄзїЃЌзюжеаЮГЩПЭЛЇЫљашЕФжЧФмгявєбЕСЗЪ§ОнМЏЁЃ
ЃЈ2ЃЉМЦЫуЛњЪгОѕ
МЦЫуЛњЪгОѕЃЈComputer VisionЃЌCVЃЉЪЧЪЙЛњЦїОпБИЁАПДЁБЕФЙІФмЕФММЪѕЃЌЫќЪЙЕУжЧФмМвОгЁЂЪжЛњЁЂАВЗРЩшБИЕШЛњЦїФмЙЛДњЬцШЫблЖдФПБъНјааЪЖБ№ЁЂИњзйКЭВтСПЕШЁЃ
вдШеГЃЩњЛюжаЕФЧщОАЮЊР§ЃЌдкЦћГЕЕФздЖЏМнЪЛЙІФмжаЃЌМЦЫуЛњЪгОѕММЪѕЪЙЕУЦћГЕФмЙЛЁАПДМћЁБВЂЪЖБ№ааГЕЙ§ГЬжаЕФИїжжааШЫЁЂТЗПіГЁОАЃЌЮЊКѓајзїГіЯргІЕФЗДгІЕьЖЈЛљДЁЃЛдкЛњГЁЁЂГЕеОАВМьжаЃЌМЦЫуЛњЪгОѕММЪѕЪЙЕУШЫСГЪЖБ№ЩшБИФмЙЛЪЖБ№БЛМьбщШЫдБЪЧЗёЮЊЦфГіЪОЕФЩэЗнжЄМўЯдЪОЕФШЫдБЁЃ
ЙЋЫОЭЈЙ§ЩшМЦбЕСЗЪ§ОнМЏНсЙЙЁЂВЩМЏЃЈШчЖЈвхКЯЪЪЕФШЫСГЁЂЖЏзїЁЂГЁОАзїЮЊВЩМЏЖдЯѓЃЌзщжЏБЛВЩМЏШЫАДеевЊЧѓХФЩуееЦЌЁЂТМжЦЪгЦЕЃЌХФЩуздЖЏМнЪЛГЁОАЪгЦЕЕШЃЉЁЂМгЙЄЃЈЖдЭМЯёЁЂЪгЦЕЮФМўНјааДђЕуЁЂЗжИюБъзЂЕШЃЉЁЂжЪМьЃЈЖдЪ§ОнМЏНјаажЪСПМьВтЃЌШчМьбщЭМЦЌЁЂЪгЦЕЮФМўИёЪНЪЧЗёе§ШЗЃЌМьВщЙтееЛЗОГЁЂЮяЬхжжРрЕФЪ§СПЪЧЗёДяБъЃЌДђЕуБъПђЕФзМШЗТЪЪЧЗёЗћКЯвЊЧѓЕШЃЉЃЛЛђепЖдПЭЛЇЬсЙЉЕФЭМЯёЁЂЪгЦЕЮФМўжДааМгЙЄЁЂжЪМьЙЄзїЃЌзюжеаЮГЩПЭЛЇЫљашЕФМЦЫуЛњЪгОѕбЕСЗЪ§ОнМЏЁЃ
ЃЈ3ЃЉздШЛгябдДІРэ
здШЛгябдДІРэЃЈNatural Language ProcessingЃЌNLPЃЉЪЧвдЛњЦїФмЙЛЯёШЫвЛбљРэНтгябдвтЭМЕФММЪѕЁЃ
вдШеГЃЩњЛюжаЕФЧщОАЮЊР§ЃЌМФЫЭПьЕнЪБЪЙгУЕФЁАжЧФмЬюаДЁБЙІФмМДдЫгУСЫздШЛгябдДІРэММЪѕЃЌдкЪфШыПђжаЬюШыећЖЮСЊЯЕаХЯЂЃЌШэМўгІгУФмЙЛРэНтгявхЃЌВЂДгжаЪЖБ№МАЬсШЁЁАЪеМўШЫЁБЁЂЁАСЊЯЕЗН
ЪНЁБЁЂЁАЕижЗаХЯЂЁБЕШЫљашаХЯЂЃЌЭъГЩздЖЏЬюаДЃЛжЧФмПЭЗўЁЂСФЬьЛњЦїШЫЕШШЫЛњНЛЛЅГЬађвВдЫгУСЫздШЛгябдДІРэММЪѕЃЌЪЙЕУГЬађЁЂЛњЦїФмЙЛЖСЖЎШЫРргябдЕФеце§втЭМЃЌВЂЯргІзіГіЗДгІЁЂЬсЙЉЗўЮёЕШЁЃЙЋЫОЭЈЙ§ЩшМЦбЕСЗЪ§ОнМЏНсЙЙЁЂВЩМЏЃЈЪеМЏздШЛгябдЮФБОЁЂЖдЛАЕШЪ§ОнаХЯЂЃЉЁЂМгЙЄЃЈЖдздШЛгябдЮФБОЪ§ОнНјааЕЅДЪЗжИюЁЂДЪадБъзЂЁЂгявхгяЗЈБъзЂЁЂЧщИаЪєадБъзЂЕШЃЉЁЂжЪМьЃЈЖдЪ§ОнМЏНјаажЪСПМьВтЃЌШчМьбщЮФБОЁЂДЪадЛђепгявхЕФБъзЂНсЙћЪЧЗёзМШЗЕШЃЉЃЛЛђепЖдПЭЛЇЬсЙЉЕФздШЛгябдЮФБОжДааМгЙЄЁЂжЪМьЙЄзїЃЌзюжеаЮГЩПЭЛЇЫљашЕФздШЛгябдбЕСЗЪ§ОнМЏЁЃ
ЃЈ4ЃЉбЕСЗЪ§ОнЯрЙиЕФгІгУЗўЮё
ЙЋЫОЛљгкздЩэЩњВњЕФбЕСЗЪ§ОнЬсЙЉЫуЗЈФЃаЭЯрЙиЕФбЕСЗЗўЮёЃЌдЫгУбЕСЗЪ§ОнбаЗЂФмСІжњСІЯТгЮПЭЛЇЭъГЩЦфЫуЗЈФЃаЭЕФгябдЭиеЙЁЂЬиЖЈЫуЗЈФЃПщЭиеЙЁЂДЙжБгІгУСьгђЭиеЙЕШЃЌЮЊПЭЛЇЖЈжЦеыЖдЬиЖЈгІгУГЁОАЕФзЈЪєЫуЗЈФЃаЭЃЌЬсИпAIММЪѕгІгУаЇЙћЁЃЧАЪіВњЦЗЁЂЗўЮёОљвдЙЋЫОЩњВњЕФзЈвЕбЕСЗЪ§ОнМЏЮЊКЫаФЛђЛљДЁЁЃЙЋЫОЭЈЙ§ЩшМЦбЕСЗЪ§ОнМЏНсЙЙЁЂзщжЏдСЯЪ§ОнВЩМЏЁЂЖдШЁЕУЕФдСЯЪ§ОнНјааМгЙЄЃЌзюжеаЮГЩПЩЙЉЫуЗЈФЃаЭбЕСЗЪЙгУЕФзЈвЕЪ§ОнМЏЁЃГЩЦЗбЕСЗЪ§ОнМЏжївЊгЩЪ§ОнЮФЕЕЁЂЫЕУїЮФЕЕЁЂММЪѕЮФЕЕШ§ВПЗжЙЙГЩЁЃвджЧФмгявєбЕСЗЪ§ОнМЏЮЊР§ЃЌГЩЦЗбЕСЗЪ§ОнМЏАќКЌдЪМВЩМЏаЮГЩЕФвєЦЕЮФМўЁЂгывєЦЕЮФМўЖдгІЕФДјгаЪБМфДСЕФБъзЂЮФМўЃЌбЕСЗЪ§ОнМЏЯрЙиЕФЩшМЦЮФЕЕЁЂбЕСЗЪ§ОнМЏЫЕУїЃЌЗЂвєДЪЕфЃЌЪ§ОнМЏВЮЪ§аХЯЂЮФМўЕШЃЌЭМЪОШчЯТЃК
ЭМЃКбЕСЗЪ§ОнМЏНсЙЙЃЈжЧФмгявєЃЉЪОР§
2.2 жївЊВњЦЗЛђЗўЮёЕФжеЖЫгІгУГЁОА
ЙЋЫОЬсЙЉЕФИпжЪСПЁЂДѓЙцФЃЁЂНсЙЙЛЏЕФбЕСЗЪ§ОнЃЌЮЊЫуЗЈФЃаЭЕФбЕСЗЭиеЙЬсЙЉСЫПЩППЕФбЕСЗ
ЫиВФЃЌжњСІAIММЪѕЪЕЯжЪЕМљгІгУМАЩЬвЕЛЏТфЕиЃЌИГФмAIММЪѕгыЪЕЬхОМУЩюЖШШкКЯЁЃЙЋЫОЬсЙЉЕФбЕСЗЪ§ОнЙуЗКгІгУгкжкЖржїСїAIВњЦЗМАжеЖЫгІгУЕФбЕСЗЙ§ГЬжаЃЌИВИЧСЫИіШЫжњЪжЁЂгявєЪфШыЁЂжЧФмМвОгЁЂжЧФмПЭЗўЁЂЛњЦїШЫЁЂгявєЕМКНЁЂжЧФмВЅБЈЁЂгявєЗвыЁЂвЦЖЏЩчНЛЁЂащФтШЫЁЂжЧФмМнЪЛЁЂжЧЛлН№ШкЁЂжЧЛлНЛЭЈЁЂжЧЛлГЧЪаЁЂЛњЦїЗвыЁЂжЧФмЮЪД№ЁЂаХЯЂЬсШЁЁЂЧщИаЗжЮіЁЂOCRЪЖБ№ЕШЖржжгІгУГЁОАЁЃ
ЭМЃКбЕСЗЪ§ОнМЏЗўЮёЕФЫуЗЈФЃаЭгІгУГЁОАЪОвт
(Жў) жївЊОгЊФЃЪН
1) гЏРћФЃЪН
гыжївЊВњЦЗМАЗўЮёРраЭЖдгІЃЌЙЋЫОЕФгЏРћФЃЪНжївЊАќРЈвдЯТШ§РрЃК
ЃЈ1ЃЉЖЈжЦЗўЮёЃКЙЋЫОИљОнПЭЛЇашЧѓЬсЙЉЖЈжЦбЕСЗЪ§ОнМЏВЂЪеШЁЗўЮёЗбЁЃдкДЫжжФЃЪНЯТЃЌЙЋЫОНіЯэгаЗўЮёЗбЪеШыЃЌВЛЯэгазюжеЩњГЩЕФбЕСЗЪ§ОнЕФжЊЪЖВњШЈЃЌВЛПЩНЋДЫРрвЕЮёЩњВњЕФбЕСЗЪ§ОнЯђЦфЫћПЭЛЇжиИДЯњЪлЁЃ
ЃЈ2ЃЉБъзМЛЏВњЦЗЃКЙЋЫОПЊЗЂздгажЊЪЖВњШЈЕФбЕСЗЪ§ОнМЏВњЦЗЃЌЭЈЙ§ЯњЪлбЕСЗЪ§ОнМЏВњЦЗЕФЪЙгУЪкШЈаэПЩЃЌЛёШЁШУЖЩзЪВњЪЙгУШЈЪеШыЁЃДЫРрбЕСЗЪ§ОнМЏвЛОПЊЗЂЭъГЩЃЌПЩЖрДЮЯњЪлВЂЛёШЁЪкШЈаэПЩЪеШыЁЃ
ЃЈ3ЃЉбЕСЗЪ§ОнЯрЙиЕФгІгУЗўЮёЃКЙЋЫОЛљгкЩњВњЕФбЕСЗЪ§ОнЬсЙЉЫуЗЈФЃаЭЯрЙиЕФФЃаЭЭиеЙМАбЕСЗЗўЮёЃЌЭЈГЃвдШэМўЪкШЈЛђШэгВМўвЛЬхЛЏаЮЪННЛИЖЫуЗЈФЃаЭЭиеЙЁЂПЊЗЂГЩЙћЃЌЛёШЁШУЖЩзЪВњЪЙгУШЈЪеШыКЭММЪѕЗўЮёЪеШыЃЌвдМАМЋЩйСПгВМўЯњЪлЪеШыЁЃ
2) ЩњВњЛђЗўЮёФЃЪН
ЃЈ1ЃЉбЕСЗЪ§ОнМЏЩњВњФЃЪН
ЙЋЫОЭЈЙ§ЩшМЦбЕСЗЪ§ОнМЏНсЙЙЁЂзщжЏдСЯЪ§ОнВЩМЏЁЂЖдШЁЕУЕФдСЯЪ§ОнНјааМгЙЄЃЌзюжеаЮГЩПЩЙЉЫуЗЈФЃаЭбЕСЗЪЙгУЕФзЈвЕЪ§ОнМЏЁЃ
ЭМЃКбЕСЗЪ§ОнЩњВњЙ§ГЬЪОвтЭМЙЋЫОЕФбЕСЗЪ§ОнЩњВњЙ§ГЬжївЊАќРЈЫФИіЛЗНкЃКЩшМЦЃЈбЕСЗЪ§ОнМЏНсЙЙЩшМЦЃЉЁЂВЩМЏЃЈЛёШЁдСЯЪ§ОнЃЉЁЂМгЙЄЃЈЪ§ОнБъзЂЃЉМАжЪМьЃЈИїЛЗНкЪ§ОнжЪСПЁЂМгЙЄжЪСПМьВтЃЉЁЃ
ЃЈ2ЃЉбЕСЗЪ§ОнЯрЙиЕФгІгУЗўЮёФЃЪН
ЙЋЫОЛљгкЦфЩњВњЕФбЕСЗЪ§ОнЬсЙЉЫуЗЈФЃаЭЯрЙибЕСЗЗўЮёЃЌжњСІЯТгЮПЭЛЇЭъГЩЦфЫуЗЈФЃаЭЕФгябдЭиеЙЁЂЬиЖЈЫуЗЈФЃПщЭиеЙЁЂДЙжБгІгУСьгђЭиеЙЕШЃЌЮЊПЭЛЇЖЈжЦеыЖдЬиЖЈаавЕКЭПквєЕФзЈЪєЫуЗЈФЃаЭЃЌЬсИпAIММЪѕгІгУаЇЙћЁЃвдФГДѓаЭПЦММЙЋЫОПЭЛЇЯюФПЮЊР§ЃЌПЭЛЇбаЗЂСЫЬиЖЈгявєЪЖБ№ЫуЗЈФЃаЭЃЌашвЊИљОнЫуЗЈФЃаЭЕФЪЕМЪГЁОАЃЈШчЗЈдКЭЅЩѓГЁОАЃЉПЊЗЂТфЕигІгУЁЃЙЋЫОГаЕЃСЫВПЗжТфЕигІгУЭиеЙЯрЙиЕФПЊЗЂЙЄзїЃЌЮЇШЦПЭЛЇЕФЫуЗЈФЃаЭКЭНгПкПЊЗЂЃЌзюжеажњПЭЛЇЫуЗЈФЃаЭЪЕЯжЖрИіТѓПЫЗчЪеМЏЭЅЩѓгявєФкШнВЂЪЕЪБзЊГЩЮФзжМЧТМШыЯЕЭГЕФЙІФмЁЃ
3) ВЩЙКФЃЪН
АДееВЩЙКЕФФкШнМАжїЬхЛЎЗжЃЌЙЋЫОЕФВЩЙКАќРЈЃК
1. Ъ§ОнЗўЮёВЩЙКЃКЙЋЫОдкЪ§ОнВЩМЏЁЂМгЙЄЛЗНкжаЃЌЯђШЫСІзЪдДЗўЮёЙЋЫОЕШВЩЙКЕФЃЌЗЧКЫаФММЪѕЛЗНкЕФдСЯЪ§ОнВЩМЏЁЂБъзЂЗўЮёЁЃ
2. ИкЮЛЗўЮёВЩЙКЃКжївЊеыЖдСйЪБадЕФЁЂВЛЩшГЄЦкИкЮЛЕФвЕЮёСьгђЕФЭтАќВЩЙКЃЌШчБЃНрЁЂСйЪБеаЦИЗўЮёЁЂЩйСПЪЕЯАЩњеаЦИЕШЁЃ
3. ЦфЫћВЩЙКЃК
ЃЈ1ЃЉбЕСЗЪ§ОнЩњВњЫљашЕФзЪВњЃЌжївЊАќРЈШэЁЂгВМўЩшБИМАЦфЫћашЧѓЮяЦЗВЩЙКЃЛ
ЃЈ2ЃЉШеГЃдЫгЊЫљашЕФзЪВњМАЮяЦЗЃЌШчАьЙЋгУЗПЁЂГЕСОЁЂАьЙЋМвОпЁЂМЦЫуЛњЩшБИЕШЃЛ
ЃЈ3ЃЉШеГЃзЈЯюЗўЮёВЩЙКЕШЃЌжївЊАќРЈЩѓМЦЗўЮёЁЂЛсвщЗўЮёЁЂВюТУЗўЮёЕШЁЃЩЯЪідСЯЪ§ОнВЩМЏЁЂМгЙЄЛЗНкЫљЩцМАЕФЪ§ОнЗўЮёВЩЙКЃЌЮЊЙЋЫОзюжївЊЕФВЩЙКРрБ№ЃЌгЩВЩЙКВП
ИКд№ЃЛИїВПУХИкЮЛЗўЮёВЩЙКгЩШЫСІзЪдДВПИКд№ЃЛЦфгрШеГЃдЫгЊЯрЙиЕФзЪВњЮяЦЗВЩЙКЁЂзЈЯюЗўЮёВЩЙКЕШЗЧвЕЮёВЩЙКгЩааеўВПИКд№ЁЃВЦЮёВПИКд№ВЮгыВЩЙКЙЉгІЩЬЕФхрбЁЁЂМрЖНгыЙмРэЃЌВЂЖдВЩЙКЗбгУНјааКЫЫуМАНсЫуЁЃ
ОЙ§ЖрФъЕФЗЂеЙЃЌЙЋЫОвбОНЈЩшгаЭъЩЦЕФЁЖЙЉгІЩЬЙмРэжЦЖШЁЗЁЂЁЖВЩЙКЙмРэжЦЖШЁЗЁЂЁЖвЕЮёВЩЙКЪЕЪЉЯИдђЁЗЁЂЁЖИкЮЛЗўЮёВЩЙКЪЕЪЉЯИдђЁЗЕШФкВПЙцЗЖжЦЖШЃЌЩшСЂгаЭъЩЦЕФВЩЙКСїГЬКЭЬхЯЕЃЌВЂгыжївЊЕФЙЉгІЩЬаЮГЩСЫСМКУЮШЖЈЕФГЄЦкКЯзїЙиЯЕЁЃ
4) ЯњЪлФЃЪН
ЙЋЫОВЩгУжБНгЖдНгВЂЗўЮёПЭЛЇЕФжБЯњФЃЪННјаагЊЯњЃЌЗћКЯаавЕЭЈааЙпР§ЁЃЙЋЫОвдИпЦЗжЪЕФбЕСЗЪ§ОнМЏМАЯрЙиЗўЮёЮќв§ПЭЛЇЃЌВЂдкГжајЗўЮёПЭЛЇЕФЙ§ГЬжаЬсЩ§ЗўЮёМлжЕКЭПЭЛЇ№ЄЖШЁЃЙЋЫОЭЈЙ§жБНгАнЗУЧБдкПЭЛЇЁЂПкБЎДЋВЅЁЂВЮгыбЇЪѕЛсвщКЭаавЕеЙЛсЁЂЙйЗНЭјеОКЭздУНЬхеЙЪОЕШЗНЪННЈСЂЦЗХЦжЊУћЖШЁЂгыПЭЛЇНЈСЂСЊЯЕЃЌКѓајдйЭЈЙ§ЩЬЮёЬИХаЁЂеаЭЖБъЕШаЮЪНЛёШЁОпЬхвЕЮёЛњЛсЁЃ
(Ш§) ЫљДІаавЕЧщПі
1. аавЕЕФЗЂеЙНзЖЮЁЂЛљБОЬиЕуЁЂжївЊММЪѕУХМї
ИљОнЙњМвЭГМЦОжЁЖеНТдадаТаЫВњвЕЗжРрЃЈ2018ЃЉЁЗЃЌЙЋЫОЫљДгЪТЕФбЕСЗЪ§ОнЩњВњвЕЮёЪєгкЁАаТвЛДњаХЯЂММЪѕВњвЕЁЊаТаЫШэМўКЭаТаЭаХЯЂММЪѕЗўЮёЁЊаТаЭаХЯЂММЪѕЗўЮёЁЊаХЯЂДІРэКЭДцДЂжЇГжЗўЮёЁЊЪ§ОнМгЙЄДІРэЗўЮёЁБаавЕЃЌЪЧЙњМвжиЕужЇГжЕФЁАаТвЛДњаХЯЂММЪѕСьгђЁБЕФеНТдадаТаЫВњвЕЁЃЙЋЫОЭЈЙ§ЩшМЦбЕСЗЪ§ОнМЏНсЙЙЁЂжДааЪ§ОнВЩМЏЁЂМгЙЄДІРэЙ§ГЬЃЌЩњВњгУгкЫуЗЈФЃаЭПЊЗЂбЕСЗгУЭОЕФзЈвЕЪ§ОнМЏЃЌВЂвдШэМўаЮЪНЯђПЭЛЇНЛИЖЃЌЫљЪєаавЕЮЊШэМўКЭаХЯЂММЪѕЗўЮёвЕЁЃ
ИљОнжаЙњжЄМрЛсАфВМЕФЁЖЩЯЪаЙЋЫОаавЕЗжРржИв§ЁЗЃЈ2012ФъаоЖЉЃЉЃЌЙЋЫОЫљЪєаавЕЮЊЁАШэМўКЭаХЯЂММЪѕЗўЮёвЕЁБЃЌаавЕДњТыЮЊЁАI65ЁБЁЃ
1.1аавЕЕФЗЂеЙНзЖЮЁЂЛљБОЬиЕу
1) бЕСЗЪ§ОнзїЮЊAIЫуЗЈЗЂеЙКЭбнНјЁАШМСЯЁБЕФзїгУМЬајЭЙЯд
дкAIВњвЕСДжаЃЌЫуЗЈЁЂЫуСІКЭЪ§ОнЙВЭЌЙЙГЩММЪѕЗЂеЙЕФШ§ДѓКЫаФвЊЫиЁЃдкЕБЧАШЫЙЄжЧФмаавЕЗЂеЙНјГЬжаЃЌгаМрЖНЕФЩюЖШбЇЯАЫуЗЈЪЧЭЦЖЏШЫЙЄжЧФмММЪѕШЁЕУЭЛЦЦадЗЂеЙЕФЙиМќММЪѕРэТлЃЌЖјДѓСПбЕСЗЪ§ОнЕФжЇГХдђЪЧгаМрЖНЕФЩюЖШбЇЯАЫуЗЈЪЕЯжЕФЛљДЁЃЌбЕСЗЪ§ОндчвбГЩЮЊЫуЗЈФЃаЭЗЂеЙКЭбнНјЕФЁАШМСЯЁБЁЃЫуЗЈФЃаЭДгММЪѕРэТлЕНгІгУЪЕМљЕФТфЕиЙ§ГЬвРРЕгкДѓСПЕФбЕСЗЪ§ОнЃЌ2012-2016ФъЦкМфЃЌШЫЙЄжЧФмаавЕВЛЖЯгХЛЏЫуЗЈдіМгЩюЖШЩёОЭјТчВуМЖЃЌРћгУДѓСПЕФЪ§ОнМЏбЕСЗЬсИпЫуЗЈОЋзМадЃЌImageNetЪ§ОнМЏЕФГЌЙ§1,400ЭђеХбЕСЗЭМЦЌКЭ1,000гржжЗжРрБудкЦфжаЦ№ЕНживЊзїгУЁЃ2021
ФъЃЌШЋЧђШЫЙЄжЧФмКЭЛњЦїбЇЯАСьгђзюШЈЭўЕФбЇепжЎвЛЮтЖїДяНЬЪкЬсГіЖўАЫЖЈТЩЃКAIбаОП80%ЕФЙЄзїгІИУЗХдкЪ§ОнзМБИЩЯЃЌШЗБЃЪ§ОнжЪСПЪЧзюживЊЕФЙЄзїЃЛвЕНчШчЙћИќЖрЕиЧПЕївдЪ§ОнЮЊжааФЖјВЛЪЧвдФЃаЭЮЊжааФЃЌФЧУДЛњЦїбЇЯАЕФЗЂеЙЛсИќПьЁЃШЛЖјЃЌДгздШЛЪ§ОндДМђЕЅЪеМЏШЁЕУЕФдСЯЪ§ОнВЂВЛФмжБНггУгкгаМрЖНЕФЩюЖШбЇЯАЫуЗЈбЕСЗЃЌБиаыОЙ§зЈвЕЛЏЕФВЩМЏЁЂМгЙЄЃЌаЮГЩЯргІЕФЙЄГЬЛЏбЕСЗЪ§ОнМЏКѓВХФмЙЉЩюЖШбЇЯАЫуЗЈЕШбЕСЗЪЙгУЁЃФПЧАЃЌгІгУгаМрЖНбЇЯАЕФЫуЗЈЖдгкбЕСЗЪ§ОнЕФашЧѓдЖДѓгкЯжгаЕФБъзЂаЇТЪКЭЭЖШыдЄЫуЃЌЛљДЁЪ§ОнЗўЮёНЋГжајЪЭЗХЦфЖдгкЫуЗЈФЃаЭЕФЛљДЁжЇГХМлжЕЁЃ
2) AIВњвЕЖдбЕСЗЪ§ОнЗўЮёЕФашЧѓГжајВњЩњЁЂЙцФЃМЬајРЉДѓAIВњвЕЖдбЕСЗЪ§ОнЕФашЧѓжївЊРДдДгкГЩЪьЫуЗЈФЃаЭЕФЭиеЙадашЧѓКЭаТЩњЫуЗЈФЃаЭЕФЧАеАадашЧѓЁЃдкГЩЪьЕФЭиеЙадашЧѓЗНУцЃЌMckinsey Global InstituteЕФбаОПБЈИцБэУїЃК
ЩюЖШбЇЯАФЃаЭЖдбЕСЗЪ§ОнЕФЪ§ОнСПЁЂЖрбљадКЭИќаТЫйЖШЗНУцЬсГіНЯИпвЊЧѓЁЃЮЊГфЗжЗЂЛгММЪѕЧБФмЃЌЩюЖШбЇЯАФЃаЭашвЊКЃСПЧвКИЧЭМЯёЁЂЪгЦЕМАгявєдкФкЕШЖржжРраЭЕФбЕСЗЪ§ОнНјааФЃаЭбЕСЗЁЃДЫЭтЃЌШЫЙЄжЧФмММЪѕвЊЧѓЫуЗЈФЃаЭИљОнЧБдкЕФгІгУГЁОАБфЛЏЖјГжајИќаТЃЌвђДЫЃЌЫуЗЈФЃаЭЫљЪЙгУЕФбЕСЗЪ§ОнврашвЊЖЈЦкИќаТЁЃОпЬхЖјбдЃЌдМ1/3ЕФЫуЗЈФЃаЭУПдТжСЩйИќаТвЛДЮЃЌдМ1/4ЕФЫуЗЈФЃаЭУПШежСЩйИќаТвЛДЮЃЌЫуЗЈФЃаЭГжајИќаТЕФЬиЕуНЋНјвЛВНЭиеЙИїСьгђбЕСЗЪ§ОнЕФашЧѓПеМфЁЃ
ЖјдкаТЩњЕФЧАеАадашЧѓЗНУцЃЌЫцзХШЫЙЄжЧФмЩЬвЕЛЏНјГЬЕФбнНјЃЌаТаЫгІгУГЁОАШчжЧФмМнЪЛЁЂжЧСЊЭјAIoTЁЂAI PaaSЁЂВњвЕЛЅСЊЭјЕШНЋеЙЯжГіОоДѓЕФЗЂеЙЧБСІЃЌВЂж№ВНДйНјAIММЪѕКЭЫуЗЈФЃаЭЕФгХЛЏКЭДДаТЁЃвђДЫЃЌдкДДаТгІгУГЁОАКЭаТаЭЫуЗЈЕФДјЖЏЯТЃЌОпгаЧАеАадЕФбЕСЗЪ§ОнВњЦЗКЭИпЖЈжЦЛЏЕФбЕСЗЪ§ОнЗўЮёашЧѓНЋж№ВНГЩЮЊжїСїЁЃ
3) ШЋЧђКЭжаЙњAIЛљДЁЪ§ОнЗўЮёаавЕЙцФЃГжајРЉеХ
i. ШЋЧђКЭжаЙњAIВњвЕЪаГЁЙцФЃ
ОЙ§ЖрФъЕФЗЂеЙЃЌШЫЙЄжЧФмММЪѕвбдкШЫЛњНЛЛЅЁЂжЧФмМвОгЁЂжЧФмМнЪЛЁЂжЧЛлН№ШкЁЂжЧФмАВЗРЕШЖрИіСьгђЪЕЯжММЪѕТфЕиЃЌЧвгІгУГЁОАгњРДгњЗсИЛЃЌAIВњвЕвбНјШыШЋЗНЮЛЩЬвЕЛЏЕФЗЂеЙНзЖЮЁЃ
ИљОнЙњМЪЪ§ОнЙЋЫОЃЈIDCЃЉЕФЪ§ОнЃЌ2021ФъЃЌШЋЧђШЫЙЄжЧФмЪаГЁЙцФЃНЋДяЕН885.7вкУРдЊЃЌдЄМЦ2025ФъНЋДяЕН2,218.7вкУРдЊЃЌФъИДКЯдіГЄТЪДяЕН26.2%ЁЃ
Ъ§ОнРДдДЃКЙњМЪЪ§ОнЙЋЫОЃЈIDCЃЉЕБЧАЮвЙњШЫЙЄжЧФмВњвЕМгЫйЗЂеЙЃЌДгЛљДЁжЇГХЁЂКЫаФММЪѕЕНаавЕгІгУЕФВњвЕСДЬѕЛљБОаЮГЩЃЌвЛХњДДаТЛюдОЁЂЬиЩЋЯЪУїЕФДДаТЦѓвЕМгЫйГЩГЄЃЌаТФЃЪНЁЂаТвЕЬЌВЛЖЯгПЯжЃЌећЬхГЪЯжХюВЊЗЂеЙЬЌЪЦЁЃеўВпжЇГжЁЂЭЖзЪв§ЕМКЭОоЭЗВМОжНЋЭЦЖЏжаЙњAIВњвЕЕФНсЙЙЕїећЃЌНјвЛВНРЉДѓЪаГЁЙцФЃЁЃИљОнЙњМЪЪ§ОнЙЋЫОЃЈIDCЃЉЕФЪ§ОнЃЌжаЙњШЫЙЄжЧФмЪаГЁЙцФЃдЄМЦ2025ФъгаЭћДя184.3вкУРдЊЃЌФъИДКЯдіГЄТЪДяЕН24.4%ЁЃ
Ъ§ОнРДдДЃКЙњМЪЪ§ОнЙЋЫОЃЈIDCЃЉii. ШЋЧђКЭжаЙњAIЛљДЁЪ§ОнЗўЮёаавЕЗЂеЙЧщПіМАЙцФЃШЋЧђЛљДЁЪ§ОнЗўЮёаавЕДІгкПьЫйГЩГЄЦкЃЌЪаГЁЙцФЃОпгаНЯДѓЕФдіГЄПеМфЁЃгІгУГЁОАЕФДДаТКЭЛњЦїбЇЯАЫуЗЈЕФСїаажБНгДјЖЏСЫбЕСЗЪ§ОнашЧѓЕФДѓЗљдіГЄЃЌетжжЧїЪЦЕМжТбЕСЗЪ§ОнФбвдЛёШЁКЭЪ§
ОнПЦбЇМвЁЂЪ§ОнЙЄГЬЪІЕШШЫСІзЪдДЯЁШБГЩЮЊжЦдМAIВњвЕЗЂеЙЕФСНДѓЬєеНЁЃИљОнDimensionalResearchЕФШЋЧђЕїбаБЈИцЃЌ72%ЕФЪмЗУепШЯЮЊжСЩйЪЙгУГЌЙ§10ЭђЬѕбЕСЗЪ§ОнНјааФЃаЭбЕСЗЃЌВХФмБЃжЄФЃаЭгааЇадКЭПЩППадЃЌ96%ЕФЪмЗУепдкбЕСЗФЃаЭЕФЙ§ГЬжагіЕНбЕСЗЪ§ОнжЪСПВЛМбЁЂЪ§СПВЛзуЁЂЪ§ОнБъзЂШЫдБВЛзуЕШФбЬтЁЃЮЊгІЖдбЕСЗЪ§ОнЫљДјРДЕФЖрЗНУцЬєеНЃЌAIЦѓвЕПЊЪМДгЕкШ§ЗНЙКТђдСЯЪ§ОнЪеМЏЁЂбЕСЗЪ§ОнЩњВњКЭЪ§ОнзЈМвзЩбЏЕШЗўЮёЃЌЕїбаНсЙћжИГіЃЌЭтАќЗўЮёФмЙЛгааЇМгПьЫуЗЈФЃаЭТфЕигІгУЕФЫйЖШЁЃвђДЫЃЌЕУвцгкбЕСЗЪ§ОнашЧѓдіГЄКЭЖдЭтВЩЙКвтЪЖЕФаЮГЩЃЌШЋЧђЛљДЁЪ§ОнЗўЮёаавЕНјШыПьЫйГЩГЄЦкЃЌЪаГЁЙцФЃОпгаНЯДѓЕФдіГЄЧБСІЁЃ
Ъ§ОнРДдДЃКDimensional ResearchДгAIВњвЕСДЕФЗЂеЙЧщПіКЭЮДРДЗЂеЙЧїЪЦРДПДЃЌжаЙњЛљДЁЪ§ОнЗўЮёаавЕЕФЪаГЁЙцФЃНЋВЛЖЯРЉДѓЁЃвЛЗНУцЃЌЫцзХЫуЗЈФЃаЭЁЂММЪѕРэТлКЭгІгУГЁОАЕФгХЛЏКЭДДаТЃЌAIВњвЕЖдбЕСЗЪ§ОнЕФЭиеЙадашЧѓКЭЧАеАадашЧѓОљПьЫйдіГЄЃЛСэвЛЗНУцЃЌЫцзХаавЕФкЖдбЕСЗЪ§ОнашЧѓРраЭЕФдіМгвдМАЖдЗўЮёБъзМвЊЧѓЕФЬсИпЃЌВњвЕСДЕФзЈвЕЛЏЗжЙЄНЋгњМгЧхЮњЃЌзЈвЕЛЏЕФбЕСЗЪ§ОнЗўЮёЬсЙЉЩЬНЋАчбнИќМгживЊЕФНЧЩЋЁЃИљОнЙњМЪЪ§ОнЙЋЫОЃЈIDCЃЉ2022Фъ3дТЗЂВМЕФЁЖIDC Worldwide Artificial Intelligence SpendingGuideЁЗдЄВтЃЌ2025ФъжаЙњШЫЙЄжЧФмЪаГЁЙцФЃгаЭћДяЕН184.3вкУРдЊЃЈдМ1,200вкШЫУёБвЃЉЃЌЦфжаЃЌЙигкЛљДЁЪ§ОнВПЗжЃЌИљОнIDCЗЂВМЕФЁЖ2021ФъжаЙњШЫЙЄжЧФмЛљДЁЪ§ОнЗўЮёЪаГЁбаОПБЈИцЁЗЃЌдЄМЦжаЙњAIЛљДЁЪ§ОнЗўЮёЪаГЁЙцФЃНќ5ФъРДЕФИДКЯФъдіГЄТЪДяЕН47%ЃЌдЄЦк2025ФъНЋЭЛЦЦ120вкдЊЃЌДяЕНжаЙњШЫЙЄжЧФмЪаГЁжЇГізмЖюЕФдМ10%ЁЃЭЌЪБЃЌИљОнЁЖIDC Worldwide Artificial Intelligence SpendingGuideЁЗЕФдЄВтЃЌ2025ФъШЋЧђШЫЙЄжЧФмЪаГЁЙцФЃНЋДяЕН2,218.7вкУРдЊЃЌЛљДЁЪ§ОнЗўЮёАхПщвВНЋЪЧЦфживЊЕФзщГЩВПЗжжЎвЛЁЃ
Ъ§ОнРДдДЃКЙњМЪЪ§ОнЙЋЫОЃЈIDCЃЉ
4) вджЧФмМнЪЛЮЊДњБэЕФДЙжБСьгђЖдбЕСЗЪ§ОнашЧѓе§дкаЫЦ№ЃЌЪаГЁЙцФЃПЩЙл
ЕБЧАAIММЪѕПЊЪМЙуЗКгІгУгкВЛЭЌВњвЕЃЌеЙЯжГіПЩЙлЕФЩЬвЕМлжЕКЭОоДѓЕФЗЂеЙЧБСІЃЌЮЊЪ§ОнЗўЮёаавЕЬсЙЉОоДѓЕФЗЂеЙКьРћЁЃВњвЕЛЏгІгУаТВњЦЗЁЂаТгІгУЁЂаТГЁОАВуГіВЛЧюЃЌВњЩњСЫДѓСПаТаЫДЙжБСьгђЕФЛљДЁЪ§ОнашЧѓЃЌетЦфжагШвджЧФмМнЪЛЮЊДњБэЕФВњвЕМЖгІгУГЪЯжПьЫйдіГЄЬЌЪЦЃЌЮЊЪ§ОнЗўЮёЕФЗЂеЙЬсЙЉСЫГЄЦкЯђКУЕФЛљБОУцЁЃЫцзХжЧФмЛЏЁЂздЖЏЛЏММЪѕВЛЖЯГЩЪьЃЌЦћГЕВњЦЗе§дкЯђжЧФмвЦЖЏжеЖЫПьЫйбнНјЁЃЭЌЪБЃЌдкжЧФмСЊЭјММЪѕЕФЭЦЖЏЯТЃЌжЧФмЦћГЕНЋж№НЅНгСІГЩЮЊГЫгУГЕЪаГЁжажївЊЕФдіГЄЖЏСІЁЃдкЦћГЕжЧФмЭјСЊЛЏЕФБфИяжаЃЌЦћГЕЕчзгЁЂШэМўЁЂЫуЗЈЕШМлжЕНЋвђжЧФмМнЪЛММЪѕЖјЯджјЬсЩ§ЁЃЯШНјЕФЭЈбЖЁЂМЦЫуЛњЁЂШЫЙЄжЧФмЕШММЪѕВЛЖЯгІгУдкжЧФмМнЪЛЦћГЕжаЃЌГЩЮЊгњМгживЊЕФЩњВњвЊЫиЁЃЖјдкжЧФмМнЪЛЙІФмЪЕЯжЕФЙ§ГЬжаЃЌЪ§ОнАчбнзХжСЙиживЊЕФНЧЩЋЁЃвдЪЕЯжжЧФмМнЪЛЫљВЛПЩгтдНЕФЕквЛЛЗНк--ЛЗОГИажЊЮЊР§ЃЌжЧФмМнЪЛГЕСОЭЈЙ§ИїРрДЋИаЦїШчЩуЯёЭЗЁЂКСУзВЈРзДяЁЂГЌЩљВЈРзДяЁЂМЄЙтРзДяЕШЛёШЁГЕСОжмБпаХЯЂЃЌВњЩњЭМЦЌЪ§ОнЁЂЪгЦЕЪ§ОнЁЂЕудЦЭМЯёЁЂЕчДХВЈЕШаХЯЂЃЌШЅГ§дыЕуаХЯЂКѓРћгУВЛЭЌРраЭЪ§ОнаЮГЩШпгрЭЌЪБЬсЩ§ИажЊОЋЖШКЭТГАєадЁЃЖдгкВЛЭЌМЖБ№жЧФмМнЪЛЦћГЕКЭМнЪЛШЮЮёЖјбдЃЌашвЊЕФДЋИаЦїРраЭЁЂЪ§СПКЭадФмвВгаЫљЧјБ№ЁЃетОЭвтЮЖзХЛёШЁИпжЪСПЁЂДѓЙцФЃЁЂЖржжРрЁЂЧПЬиеїЕФбЕСЗЪ§ОнЪЧЪЕЯжИпОЋзМЖШЛЗОГИажЊЁЂНјЖјЪЕЯжИпжЪСПжЧФмМнЪЛЕФЙиМќЁЃ
ИљОнжаН№ЙЋЫОбаОПВПдЄВтЃЌНідкИпМЖБ№здЖЏМнЪЛСьгђЃЌЫцзХТфЕиГЁОАЕФЙуЗКЛЏвдМАЩЬвЕЛЏНјГЬЕФЬсЫйЃЌЪаГЁЙцФЃПЩДяЭђвкдЊМЖБ№ЁЃОпЬхгІгУГЁОАПЩЗжЮЊ2CЃЈГЫгУГЕЃЉЁЂ2BЃЈЩЬгУГЕЃЉКЭ2GЃЈеўИЎЙњЦѓЃЉЕШЁЃИљОнжаН№ЙЋЫОбаОПВПВтЫуЃЌдЄМЦЮвЙњИпЫйГЧМЪЮяСїЪаГЁДя3.3ЭђвкдЊЃЌздЖЏМнЪЛГі
ааЗўЮёЪаГЁНќ1.7ЭђвкдЊЃЌПѓЧјЮоШЫМнЪЛЪаГЁНќ6,700вкдЊЃЌЮоШЫФЉЖЫХфЫЭЪаГЁДя1,700вкдЊЁЃФПЧАЃЌжЧФмМнЪЛЪ§ОнЗўЮёашЧѓДІгкМгЫйЦ№ВННзЖЮЃЌЪаГЁЙцФЃЩаЮоЗЈзМШЗЙРСПЃЌЕЋЫцзХЪ§ОнжЎгкAIгІгУММЪѕбаЗЂЕФзїгУЕФЬсЩ§ЃЌвРЭагкжЧФмМнЪЛОоДѓЕФЪаГЁПеМфЃЌжЧФмМнЪЛЪ§ОнЗўЮёСьгђЕФЪаГЁЙцФЃЭЌбљОпгаЙуРЋЧАОАЁЃГ§жЧФмМнЪЛСьгђЭтЃЌЦфЫћДЙжБаавЕЃЈР§ШчжЧЛлН№ШкЁЂЙЄвЕЛЅСЊЭјЕШЃЉКЭеўЦѓСьгђвВНЋГЩЮЊбЕСЗЪ§ОнЪЕЯжЙцФЃЛЏгІгУЕФживЊЗНЯђЃЌЪЧЩаЮДЙРСПЕФаТдіЪаГЁЃЌЧвУПвЛИіДЙжБаавЕФкВПОљгажюЖрЯИЗжЃЌвђДЫЪаГЁШнСПЗЧГЃПЩЙлЁЃ
5) ЙњМвеўВпЖЅВув§СьЁЂаавЕжиЕужЇГжгыЙцЗЖАВШЋМрЙмаЭЌВЂНјЕБЧАЃЌЮвЙњвбОПЊЪМНјШыгЩЙЄвЕОМУТѕЯђЪ§зжОМУЗЂеЙЕФЁАаТНзЖЮЁБЃЌЙњМвИпЖШжиЪгЪ§зжОМУЃЌЖјЪ§ОнвЊЫиЪЧЪ§зжОМУЩюЛЏЗЂеЙЕФКЫаФв§ЧцЁЃЯАНќЦНзмЪщМЧдкжаЙВжабыеўжЮОжОЭЪЕЪЉЙњМвДѓЪ§ОнеНТдНјааЕкЖўДЮМЏЬхбЇЯАЪБдјжИГіЃКЪ§ОнЪЧаТЕФЩњВњвЊЫиЃЌЪЧЛљДЁадзЪдДКЭеНТдадзЪдДЃЌвВЪЧживЊЩњВњСІЃЌвЊЙЙНЈвдЪ§ОнЮЊЙиМќвЊЫиЕФЪ§зжОМУЁЃ2022Фъ1дТ12ШеЃЌЙњЮёдКгЁЗЂЁЖЁАЪЎЫФЮхЁБЪ§зжОМУЗЂеЙЙцЛЎЁЗУїШЗЬсГіЃКЪ§ОнвЊЫиЪЧЪ§зжОМУЩюЛЏЗЂеЙЕФКЫаФв§ЧцЃЌМсГжвдЪ§зжЛЏЗЂеЙЮЊЕМЯђЃЌГфЗжЪЭЗХвЊЫиМлжЕЃЌМЄЛюЪ§ОнвЊЫиЧБФмЁЃЫцзХЪ§ОнвЊЫизїЮЊЙњМвМЖеНТдзЪдДЕиЮЛВЛЖЯЭЙЯдЃЌвЛЯЕСаЙњМвв§СьгыаавЕЙФРјеўВпВЛЖЯЭЦНјЃЌЪ§ОнзїЮЊЕБЧАзюОпЪБДњЬиеїЕФЩњВњвЊЫиЃЌГЩЮЊжиЕужЇГжСьгђЃЌЮЊЪ§ОнзЪдДВњвЕДјРДСЫОоДѓЕФЗЂеЙЛњгіЁЃгыДЫЭЌЪБЃЌЫцзХЪ§зжОМУЙцФЃЕФПьЫйРЉеХЃЌЪ§зжММЪѕЙуЗКгІгУКЭЗЈТЩЙцЗЖЦєЖЏТфЕиЕФЯрЛЅНЛШквВГЩЮЊЪ§ОнВњвЕНЁПЕЗЂеЙЕФБиШЛЧїЪЦЃЌНЈЩшЙцЗЖЁЂАВШЋЁЂКЯЙцЁЂИпжЪСПЕФЪ§зжОМУвбГЩЮЊЦШЧавЊЧѓЃЌЙњМвТНајГіЬЈАќРЈЁЖЪ§ОнАВШЋЗЈЁЗЁЂЁЖИіШЫаХЯЂБЃЛЄЗЈЁЗЁЂЁЖЦћГЕЪ§ОнАВШЋЙмРэШєИЩЙцЖЈЃЈЪдааЃЉЁЗЕШжїСїЗЈТЩЗЈЙцЃЌЮЊНтОіЪ§ОнАВШЋЮЪЬтЁЂОЛЛЏаавЕПьЫйЗЂеЙжаЕФВЛСМТвЯѓЬсЙЉСЫЧаЪЕПЩааЕФЗЈТЩвРОнЁЃжївЊаавЕеўВпМАЗЈТЩЗЈЙцШчЯТЃК
| ађКХ | ЗЂВМЪБМф | ЗЂЮФЛњЙи | жївЊаавЕеўВпМА ЗЈТЩЗЈЙц | ЯрЙиФкШн |
| 1 | 2022Фъ 1дТ | ЙњЮёдК | ЁЖЁАЪЎЫФЮхЁБЪ§зжОМУЗЂеЙЙцЛЎЁЗ | УїШЗжИГіЪ§ОнвЊЫиЪЧЪ§зжОМУЩюЛЏЗЂеЙЕФКЫаФв§ЧцЃЌМсГжвдЪ§зжЛЏЗЂеЙЮЊЕМЯђЃЌГфЗжЪЭЗХвЊЫиМлжЕЃЌМЄЛюЪ§ОнвЊЫиЧБФмЁЃ |
1.2 аавЕЕФжївЊММЪѕУХМї
ЫцзХAIММЪѕВЛЖЯбнНјЁЂВњвЕгІгУВЛЖЯЗсИЛЃЌбЕСЗЪ§ОнЕФЪаГЁашЧѓГЪЯжЬхСПЁЂФбЖШЁЂИДдгадЁЂКЯЙцадГжајЩЯЩ§ЕФЧїЪЦЃЌЪ§ОнЗўЮёЩЬаыОпБИЖдШЫЙЄжЧФмКЫаФЫуЗЈЕФРэНтФмСІЁЂЧАеАадЕФзЈвЕЪ§ОнМЏЩшМЦФмСІЁЂЗсИЛЕФгябдИВИЧФмСІМАГЁОАВЩМЏФмСІЁЂвдМАЫуЗЈИЈжњЪ§ОнЩњВњФмСІЃЌетЪЙЕУаавЕЕФММЪѕУХМїГжајЬсЩ§ЃЌОпЬхЬхЯжЮЊЃК
1) дкбЕСЗЪ§ОнбаЗЂЁЂЩњВњШЋСїГЬжаЕФЫуЗЈШЋУцНщШы
ЫцзХAIММЪѕгІгУТфЕиЕФЙцФЃЛЏаЇгІЭЙЯдЃЌПЭЛЇЖдгкЪ§ОнЙцФЃКЭДІРэаЇТЪЕФвЊЧѓВЛЖЯЬсЩ§ЃЌЪ§ОнЗўЮёЩЬаыдкбаЗЂЁЂЩњВњСїГЬжаШЋУцв§ШыЫуЗЈвдЪЕЯжИпаЇЁЂКЯРэЕФШЫЛњазїФЃЪНЃЌНјЖјЪЕЯжНЕБОдіаЇЕФФПБъЁЃвЛАуЖјбдЃЌдкбЕСЗЪ§ОнбаЗЂЁЂЩњВњШЋСїГЬжаШкШыЫуЗЈММЪѕЃЌПЩгУгкМьВщбЕСЗЪ§ОнМЏ
| 2 | 2021Фъ 8дТ | ЙњМвЛЅСЊЭјаХЯЂАьЙЋЪвЕШ | ЁЖЦћГЕЪ§ОнАВШЋЙмРэШєИЩЙцЖЈЃЈЪдааЃЉЁЗ | зїЮЊЦћГЕЪ§ОнАВШЋСьгђГіЬЈЕФЕквЛЗнгаеыЖдадЕФЙмРэЙцЖЈЃЌУїШЗСЫЦћГЕЪ§ОнДІРэепЕФд№ШЮКЭвхЮёЃЌЙцЗЖЦћГЕЪ§ОнДІРэЛюЖЏЃЌЖдЗРЗЖЛЏНтЦћГЕЪ§ОнАВШЋЗчЯеЁЂБЃеЯЦћГЕЪ§ОнвРЗЈКЯРэгааЇРћгУОпгаживЊвтвхЁЃ |
| 3 | 2021Фъ 8дТ | ЕкЪЎШ§НьШЋЙњШЫДѓГЃЮЏЛс | ЁЖИіШЫаХЯЂБЃЛЄЗЈЁЗ | НјвЛВНЯИЛЏЁЂЭъЩЦИіШЫаХЯЂБЃЛЄгІзёбЕФддђКЭИіШЫаХЯЂДІРэЙцдђЃЌУїШЗИіШЫаХЯЂДІРэЛюЖЏжаЕФШЈРћвхЮёБпНчЃЌНЁШЋИіШЫаХЯЂБЃЛЄЙЄзїЬхжЪЛњжЦЁЃ |
| 4 | 2021Фъ 6дТ | ЕкЪЎШ§НьШЋЙњШЫДѓГЃЮЏЛс | ЁЖжаЛЊШЫУёЙВКЭЙњЪ§ОнАВШЋЗЈЁЗ | ЮвЙњЪ§ОнЕФЪЙгУКЭБЃЛЄНјШыгаЗЈПЩвРЕФаТНзЖЮЃЌЙњМвЭГГяЗЂеЙКЭАВШЋФуЃЌМсГжвдЪ§ОнПЊЗЂРћгУКЭВњвЕЗЂеЙДйНјЪ§ОнАВШЋЃЌвдЪ§ОнАВШЋБЃеЯЪ§ОнПЊЗЂРћгУКЭВњвЕЗЂеЙЁЃ |
| 5 | 2021Фъ 3дТ | ЪЎШ§НьШЋЙњШЫДѓЫФДЮЛсвщ | ЁЖжаЛЊШЫУёЙВКЭЙњЙњУёОМУКЭЩчЛсЗЂеЙЕкЪЎЫФИіЮхФъЙцЛЎКЭ2035ФъдЖОАФПБъИйвЊЁЗ | ЁЖЪЎЫФЮхЙцЛЎЁЗжИГівЊМгПьЪ§зжЛЏЗЂеЙЃЌНЈЩшЪ§зжжаЙњЃЌЭЌЪБДђдьЪ§зжОМУаТгХЪЦЃЌГфЗжЗЂЛгКЃСПЪ§ОнКЭЗсИЛгІгУГЁОАгХЪЦЃЌДйНјЪ§зжММЪѕгыЪЕЬхОМУЩюЖШШкКЯЃЌИГФмДЋЭГВњвЕзЊаЭЩ§МЖЃЌДпЩњаТВњвЕаТвЕЬЌаТФЃЪНЃЌзГДѓОМУЗЂеЙаТв§ЧцЁЃЭЌЪБжИГівЊМгЧПЙиМќЪ§зжММЪѕДДаТгІгУЃКОлНЙИпЖЫаОЦЌЁЂВйзїЯЕЭГЁЂШЫЙЄжЧФмЙиМќЫуЗЈЁЂДЋИаЦїЕШЙиМќСьгђЃЛНЈЩшжиЕуаавЕШЫЙЄжЧФмЪ§ОнМЏЃЌЗЂеЙЫуЗЈЭЦРэбЕСЗГЁОАЁЃ |
| 6 | 2020Фъ 3дТ | жаЙВжабыЁЂЙњЮёдК | ЁЖжаЙВжабы ЙњЮёдКЙигкЙЙНЈИќМгЭъЩЦЕФвЊЫиЪаГЁЛЏХфжУЬхжЦЛњжЦЕФвтМћЁЗ | ЪзДЮНЋЁАЪ§ОнЁБзїЮЊЪаГЁЛЏвЊЫиаДШыЙњМвЖЅВуЩшМЦМЖБ№ЮФМўЃЌЬсГівЊМгПьХрг§Ъ§ОнвЊЫиЪаГЁЃЌЗЂЛгЪ§ОндкЪаГЁЛЏХфжУжаЕФзїгУЁЃ |
ЖдЫуЗЈФЃаЭЕФбЕСЗаЇЙћЃЌНјЖјЗДВИжИЕМбЕСЗЪ§ОнМЏЕФЩшМЦЃЛвВПЩгІгУгкбЕСЗЪ§ОнЩњВњЕФИїИіЛЗНкЃЌР§ШчЕїЖШВЛЭЌРраЭЕФБъзЂШЫдБгІЖдВЛЭЌСьгђЕФШЮЮёЁЂаЮГЩЫуЗЈздЖЏДІРэФмСІвдАяжњБъзЂШЫдБЬсЩ§аЇТЪЁЂНЕЕЭЖдШЫдБЕФвРРЕЃЈМШгаШЫдБЪ§СПЕФНЕЕЭЁЂвВгаЖдШЫдББъзЂФмСІвЊЧѓЕФНЕЕЭЃЉЃЌВЂЙЙНЈбЕСЗЪ§ОнЩшМЦЁЂМгЙЄЯрЙиЕФКЫаФММЪѕЁЃ
2) ЦНЬЈЙЄОпЙІФмМАЪЪХфадвЊЧѓГжајЬсЩ§
ЕБЧАЃЌПЭЛЇВрЕФЪ§ОнВЩМЏЁЂБъзЂашЧѓЗЖЮЇдкж№НЅЭиПэЃЌЪ§ОнВЩМЏгыБъзЂашТњзуЕФAIгІгУГЁОАБШвдЭљУїЯдИќМгЙуЗКЁЂИДдгЃЌетОЭЖдЪ§ОнЗўЮёЩЬЕФЦНЬЈЙЄОпФмСІЬсГіСЫИќИпвЊЧѓЃЌЦНЬЈЩЯДІРэЙ§ЖрДѓЙцФЃЕФЪ§ОнЁЂетаЉДІРэЙ§ЕФЪ§ОнЕФЖрбљадКЭИДдгГЬЖШШчКЮЁЂЫуЗЈв§ЧцЭЖЦБЛњжЦШчКЮНЈСЂЁЂжУаХЧјМфШчКЮЩшжУЁЂЫуЗЈдкЦНЬЈжаШчКЮгІгУЁЂЪ§ОнСїзЊЕФЙЄГЬЛЏГЬЖШШчКЮЕШЕШетаЉвђЫиЖМОіЖЈСЫЦНЬЈЕФЪЪХфадКЭФмСІШчКЮЃЌВЂзюжеОіЖЈСЫЪ§ОнДІРэЕФжЪСПЁЂаЇТЪЁЂГЩБОЁЃ
3) гявєгябдбЇЛљДЁбаОПЗНУцаыгаЩюКёЛ§Рл
АщЫцгявєММЪѕНјвЛВНЗЂеЙТфЕиЁЂВЂЯђИїааИївЕКЭИќЖрДЙжБГЁОАВЛЖЯЩјЭИЃЌЭЌЪБЪмЕНжаЙњЦѓвЕГіКЃашЧѓЁЂЙњЭтЦѓвЕЧјгђЭиеЙашЧѓСНЗНУцЕФжЇГХЃЌПЭЛЇдкЖргяжжЁЂЖрвєЩЋЁЂвєЫиМЏЁЂЗЂвєЙцдђЁЂЗЂвєДЪЕфЕШЗНУцЕФвЊЧѓдкВЛЖЯЬЇЩ§ЃЌетвтЮЖзХжЛгаФЧаЉдкгявєгябдбЇЛљДЁбаОПЗНУцЭЖШыИќЖрЁЂгЕгаЩюКёЛ§РлЕФЪ§ОнЗўЮёЩЬВХФмТњзуПЭЛЇдкетЗНУцЕФЖрдЊЛЏашЧѓЁЃ
вђДЫЃЌЪаГЁЩЯНігаМЋЩйЪ§ЦѓвЕЭЈЙ§ГЄЦкзджїбаЗЂЕФЗНЪНФмЙЛДяЕНЩЯЪіКЫаФММЪѕУХМїЃЌГЩЮЊгаФмСІЯђВЛЭЌПЭЛЇШКЬхЬсЙЉзлКЯЁЂИпаЇЁЂКЯЙцЕФЪ§ОнВњЦЗМАЗўЮёЁЃ
2. ЙЋЫОЫљДІЕФаавЕЕиЮЛЗжЮіМАЦфБфЛЏЧщПі
1) ЩюИћаавЕЖрФъЃЌгЕгаЗсИЛЕФММЪѕЛ§РлКЭаавЕОбщЃЌОпБИНЯЧПОКељгХЪЦ
КЃЬьШ№ЩљЪЧЮвЙњзюдчзЈвЕДгЪТбЕСЗЪ§ОнВњЦЗгыЗўЮёбаЗЂгыМАЯњЪлЕФжївЊЦѓвЕжЎвЛЃЌЙЋЫОЦОНшЖрФъЕФбаЗЂЛ§РлКЭДДаТЃЌВЛНіЭъГЩ930грИіздгажЊЪЖВњШЈЕФбЕСЗЪ§ОнБъзМЛЏВњЦЗМЏЕФНЈЩшЃЌдкДѓЙцФЃЁЂИпжЪСПЁЂПЩЪкШЈЪЙгУЪ§ОнПтДцСПШЋЧђЦѓвЕХХУћжаЮШОгЧАСаЃЌаЮГЩСЫДѓСПКЫаФММЪѕгыжЊЪЖВњШЈДЂБИГЩЙћЃЌВЂНЋЛљДЁбаОПЁЂЦНЬЈЙЄОпЁЂбЕСЗЪ§ОнЩњВњЕШШ§ДѓСьгђЛ§РлЕФКЫаФММЪѕГжајгІгУгкбЕСЗЪ§ОнЩњВњЕФИїИіЛЗНкЃЌдкЪ§ОнПтМмЙЙЩшМЦЁЂПЊЗЂБъзМЁЂгябдбЇЬиеїЁЂжЪМьЦРВтЕШЖрЯюММЪѕжИБъЗНУцЭЙЯдОКељгХЪЦЁЃ
ЖрФъЛ§РлЕФКЫаФММЪѕГЩЙћКЭзлКЯзЈвЕЗўЮёФмСІЃЌЪЙЕУЙЋЫОФмЙЛИќДѓЙцФЃЁЂИќгааЇТЪЁЂИќМгОЋзМЕиЩњВњAIбЕСЗЪ§ОнЃЌдкЬсЩ§здЩэВњГіаЇТЪЕФЭЌЪБвВгааЇЬсИпСЫбЕСЗЪ§ОнЖдгкПЭЛЇAIЫуЗЈФЃаЭЕФИФЩЦЁЂгХЛЏаЇЙћЁЃЙЋЫОгыAIВњвЕСДЩЯЕФИїРрЦѓвЕЁЂбаОПЛњЙЙГжајБЃГжГЄЦкЕФКЯзїЛяАщЙиЯЕЃЌНи
жЙ2021ФъЕзЃЌЦѓвЕЗўЮёПЭЛЇЪ§СПвбДяЕН695МвЃЌВњЦЗМАЗўЮёФмСІВЛЖЯЕУЕНгХжЪПЭЛЇЕФШЯПЩЃЌЮДРДЙЋЫОНЋМЬајЭъЩЦВњЦЗЗўЮёЬхЯЕЁЂЩ§МЖЗўЮёжЪСПЃЌВЛЖЯдіЧПзлКЯЪ§ОнЗўЮёФмСІОКељгХЪЦЁЃ
2) ДІгкжаЙњAIЛљДЁЪ§ОнЗўЮёаавЕЕквЛЬнЖгЃЌгЕгаЮШЙЬЕФаавЕЕиЮЛ
зїЮЊаавЕЕФЭЗВПеѓгЊЦѓвЕЃЌКЃЬьШ№ЩљдкОгЊЧщПіЁЂЪаГЁЕиЮЛЁЂММЪѕЪЕСІЁЂКЫаФОКељСІЕШЗНУцЖМеЙЪОГіУїЯдгХЪЦЃЌВЂОпгаНЯЧПЙњМЪОКељСІЁЃНќФъРДЙЋЫОНєИњAIММЪѕЗЂеЙЧїЪЦЃЌгШЦфЙизЂдкПЭЛЇзЪдДЁЂММЪѕЪЕСІЁЂВњЦЗ/ЗўЮёЕШЗНУцЕФОКељгХЪЦЃЌЪїСЂЙњФкСьЯШЛљДЁЪ§ОнЗўЮёЩЬЕФЦЗХЦаЮЯѓЃЌвдЙЎЙЬЙЋЫОЕФаавЕСьЯШЕиЮЛЁЃгыЭЌаавЕЙњФкЭтОКељЖдЪжЕФЖдБШЧщПіМАгХЪЦЬхЯжШчЯТЃК
| ЯюФП | КЃЬьШ№Щљ | Appen | ЛлЬ§ПЦММ | БъБДПЦММ |
| ОгЊЧщПі | ||||
| ГЩСЂ ФъЗн | 2005Фъ | 1996Фъ | 2011Фъ | 2016Фъ |
| ЪаГЁЕиЮЛИХЪі | ЮвЙњСьЯШЕФбЕСЗЪ§ОнВњЦЗЗўЮёзЈвЕЬсЙЉЩЬЃЌЪЧЮвЙњзюдчДгЪТбЕСЗЪ§ОнВњЦЗЗўЮёбаЗЂЯњЪлЕФЦѓвЕжЎвЛ | НЯдчДгЪТЪ§ОнзЪдДПЊЗЂЕФЪ§ОнзЪдДВњЦЗЗўЮёЬсЙЉЩЬЃЌОгЊРњЪЗНЯГЄЃЌЙцФЃЁЂЬхСПНЯДѓ | - | - |
| дБЙЄ Ъ§СП | 245 | ГЌЙ§1,125 | ЮДЙЋПЊХћТЖ | ЮДЙЋПЊХћТЖ |
| ЪаГЁ еМгаТЪ | жаЙњAIЛљДЁЪ§ОнЗўЮёаавЕЕкЖўУћЃЌКЃЬьШ№ЩљЕФЪаГЁеМгаТЪЮЊ12.9%1ЁЃ | ЮДЙЋПЊХћТЖ | ЮДЙЋПЊХћТЖ | ЮДЙЋПЊХћТЖ |
| ПЭЛЇНсЙЙМАПЭЛЇЪ§СП | ||||
| жївЊПЭЛЇ/КЯзїЛяАщЧщПі | ДѓаЭПЦММЙЋЫОЃЌШчАЂРяАЭАЭЁЂЬкбЖЁЂАйЖШЁЂзжНкЬјЖЏЁЂЮЂШэЁЂШ§аЧЕШЃЛШЫЙЄжЧФмЦѓвЕЃЌШчПЦДѓбЖЗЩЁЂЩЬЬРПЦММЁЂдЦжЊЩљЁЂКЃПЕЭўЪгЕШЃЛПЦбаЛњЙЙЃЌШчжаЙњПЦбЇдКЁЂЧхЛЊДѓбЇЁЂжаЙњПЦбЇММЪѕДѓбЇЕШ | ЮЂШэЁЂбЧТэбЗЁЂЙШИшЕШДѓаЭПЦММЙЋЫОЁЂЦћГЕГЇЩЬМАеўИЎ | ЮДЙЋПЊХћТЖ | ЮЂШэЁЂАйЖШЁЂАЂРяЁЂЬкбЖЁЂОЉЖЋЁЂЕЮЕЮЁЂзжНкЬјЖЏЁЂЭјвзЁЂ360ЁЂШ§аЧЁЂаЁХєЁЂУРЕФЁЂжаПЦДѓЁЂжаЕчПЦЁЂжаЙњвјааЕШ |
| ЯюФП | КЃЬьШ№Щљ | Appen | ЛлЬ§ПЦММ | БъБДПЦММ |
| ПЭЛЇ Ъ§СП | 695Мв ЃЈНижС2021Фъ12дТ31ШеРлМЦЃЉ | ЮДЙЋПЊХћТЖ | Ъ§ЪЎМв | 100грМв |
| ММЪѕжИБъ | ||||
| ММЪѕЪЕСІИХЪі | КЃЬьШ№ЩљзджїПЊЗЂСЫвЛЬхЛЏЪ§ОнДІРэжЇГХЦНЬЈЃЌдкЛљДЁбаОПЁЂЦНЬЈЙЄОпЁЂбЕСЗЪ§ОнЩњВњШ§ИіЮЌЖШЯТОљЛ§РлКЫаФММЪѕЃЌНЋЖрЯюОпЬхКЫаФММЪѕећКЯЮЊЙЋЫОЬигаЕФКЫаФММЪѕЬхЯЕЁЃ | AppenгЕгаШЫЙЄжЧФмИЈжњЪ§ОнзЂЪЭЦНЬЈЃЌдкШЋЧђ170ЖрИіЙњМвгы100ЖрЭђУћзЈвЕГаАќЩЬКЯзїЃЌбЕСЗЪ§ОнКИЧПЦММЁЂЦћГЕЁЂН№ШкЗўЮёЁЂСуЪлЁЂвНСЦНЁПЕКЭеўИЎЕШИїИіСьгђЁЃ | ВЩгУШЋГЬжЪСПМрПиСїГЬЃЌжДааЭъЩЦЕФБъзЂСїГЬЃЌХфКЯБЃУмЙмРэЪжЖЮЃЌЬсЙЉжЪСПЩЯГЫЕФЪ§ОнЗўЮёЁЃ | гЕгагявєКЯГЩФЃаЭКЭЫуЗЈЃЌЭЈЙ§ЫуЗЈ+зЈвЕЕФШЫЙЄЪ§ОнДІРэЗНЪНЃЌЮЊПЭЛЇЬсЙЉгХжЪЕФгявєКЯГЩЗўЮёЁЃгЕгаTOBI БъзЂЬхЯЕЃЌЭЈЙ§зджїбаЗЂЕФTTSЦРВтЯЕЭГЃЌЮЊПЭЛЇЬсЙЉИпжЪСПЕФЪ§ОнЗўЮёЁЃ |
| гІгУСьгђИВИЧ | жЧФмгявєЁЂМЦЫуЛњЪгОѕЁЂздШЛгябд | жЧФмгявєЁЂМЦЫуЛњЪгОѕЁЂздШЛгябд | жЧФмгявєЁЂМЦЫуЛњЪгОѕЁЂздШЛгябдЁЂвєРж | жЧФмгявєЁЂМЦЫуЛњЪгОѕЁЂздШЛгябдЁЂвєРж |
| гяжж/ЗНбдИВИЧФмСІ | 170грИі | ГЌЙ§235Иі | 20грИі | 10грИі |
| вбШЁЕУзЈРћЪкШЈ | 26ЯюЃЈ24ЯюЗЂУїзЈРћЁЂ1ЯюЪЕгУаТаЭзЈРћМА1ЯюЭтЙлЩшМЦзЈРћЃЉ | 2Яю | 1Яю | 4Яю |
| МЦЫуЛњШэМўжјзїШЈ Ъ§СП | 156Яю | ЮДЙЋПЊХћТЖ | 14Яю | 30Яю |
| ВњЦЗ/ЗўЮёМАЦфВржиЕу | ||||
| гЕгаЕФГЩЦЗбЕСЗЪ§ОнМЏЪ§СП | 932Иі ЃЈНижС2021Фъ12дТ31ШеРлМЦЃЉ | 291Иі | 45Иі | 179Иі |
| ЦфЫћОгЊжИБъ | ||||
| жївЊВЦЮёжИБъЃЈ2021ФъЖШ/2021ФъФЉЃЉ | ||||
| гЊвЕ ЪеШы | 2.06вкдЊШЫУёБв | 4.47вкУРдЊ | ЮДЙЋПЊХћТЖ | ЮДЙЋПЊХћТЖ |
| злКЯУЋРћТЪ | 64.01% | 39.98% | ЮДЙЋПЊХћТЖ | ЮДЙЋПЊХћТЖ |
| ОЛРћШѓ | 3,160.54ЭђдЊШЫУёБв | 2,851.9ЭђУРдЊ | ЮДЙЋПЊХћТЖ | ЮДЙЋПЊХћТЖ |
| ОЛРћТЪ | 15.31% | 6.38% | ЮДЙЋПЊХћТЖ | ЮДЙЋПЊХћТЖ |
Ъ§ОнРДдДМАЫЕУїЃК
1ЁЂAppenЁЂЛлЬ§ПЦММЁЂБъБДПЦММЪ§ОнЃКНижС2021Фъ12дТЃЌЧАЪіЙЋЫОЙйЭјМАЙЋПЊХћТЖаХЯЂЃЛЙњМвжЊЪЖВњШЈОжжаЙњМАЖрЙњзЈРћЩѓВщаХЯЂВщбЏЦНЬЈЃЈhttp://cpquery.sipo.gov.cn/ЃЉЁЂжаЙњАцШЈБЃЛЄжааФCPCCЮЂЦНЬЈЕШЙЋПЊаХЯЂВщбЏЧўЕРМАЕкШ§ЗНЛњЙЙВщбЏаХЯЂЁЃ
2ЁЂКЃЬьШ№ЩљЪ§ОнЃКГ§ЬиБ№БъзЂЭтЃЌОљЮЊНижС2021Фъ12дТ31ШеЪ§ОнЁЃ
гыAppenЯрБШЃЌКЃЬьШ№ЩљЙцФЃНЯаЁЃЌгЊЪеМАОЛРћШѓЙцФЃЁЂдБЙЄЪ§СПЕШОљЕЭгкAppenЃЌдкгяжж/ЗНбдИВИЧФмСІЗНУцвВОпБИвЛЖЈСгЪЦЃЛЫЋЗНдкбЕСЗЪ§ОнЕФВњЦЗСьгђИВИЧФмСІЯрЕБЃЛЙЋЫОдкБъзМЛЏбЕСЗЪ§ОнМЏВњЦЗДЂБИЧщПівдМАЮвЙњПЭЛЇЕФИВИЧГЬЖШЗНУцОпБИвЛЖЈгХЪЦЁЃ
гыЛлЬ§ПЦММЁЂБъБДПЦММЯрБШЃЌИљОнЙњМЪЪ§ОнЙЋЫОЃЈIDCЃЉЪ§ОнЃЌЙЋЫОЪаГЁЗнЖюдкжаЙњAIЛљДЁЪ§ОнЗўЮёаавЕХХУћЕкЖўЃЌНЯЮЊСьЯШЁЃЙЋЫОдкбЕСЗЪ§ОнИВИЧЕФгяжж/ЗНбдИВИЧФмСІЁЂБъзМЛЏбЕСЗЪ§ОнМЏВњЦЗДЂБИЪ§СПЁЂМЦЫуЛњШэМўжјзїШЈЪ§СПЗНУцОљИпгкЛлЬ§ПЦММЁЂБъБДПЦММЃЈЯогкЙЋПЊаХЯЂПЩВщбЏЗЖЮЇЃЉЃЌгХЪЦУїЯдЃЛдкВњЦЗСьгђИВИЧЗНУцЃЌГ§жЧФмгявєЁЂМЦЫуЛњЪгОѕЁЂздШЛгябдЭтЃЌБъБДПЩИВИЧвєРжРрбЕСЗЪ§ОнЃЛЙЋЫОЮДЕЅЖРСаЪОвєРжРрбЕСЗЪ§ОнЃЌЕЋгявєКЯГЩРрвЕЮёПЩЬсЙЉИшЧњКЯГЩРрЗўЮёЃЌвВвбИВИЧвєРжРрбЕСЗЪ§ОнЃЌЙЋЫОдкВњЦЗСьгђИВИЧЗНУцБШНЯЭъЩЦЁЃ
дкЪаГЁЕиЮЛЗНУцЃЌAppenЪЧНЯдчДгЪТбЕСЗЪ§ОнПЊЗЂЕФбЕСЗЪ§ОнЬсЙЉЩЬЃЌОгЊРњЪЗНЯГЄЃЌЙцФЃЁЂЬхСПЕШЯрБШКЃЬьШ№ЩљОљОпБИгХЪЦЃЛЖјЙЋЫОЪЧЮвЙњзюдчДгЪТбЕСЗЪ§ОнбаЗЂЁЂЩњВњЁЂЯњЪлЕФЦѓвЕжЎвЛЃЌдкЮвЙњЪаГЁОпБИСьЯШЕиЮЛЁЃЖрФъРДЃЌЙЋЫОЩюИћбЕСЗЪ§ОнЗўЮёСьгђЃЌАщЫцСЫжкЖрЙњФкПЭЛЇдкШЫЙЄжЧФмСьгђЬиБ№ЪЧжЧФмгявєСьгђЕФПЊЭиЁЂГЩГЄЃЌЮЊЦфГжајЬсЙЉСЫШЋЧђгяжжгявєбЕСЗЪ§ОнЕФИпжЪСПЕФБОЭСЗўЮёЃЌНЕЕЭСЫЖдЙњЭтЭЌРрбЕСЗЪ§ОнЕФвРРЕЁЃ
дкжївЊВЦЮёжИБъЗНУцЃЌЛлЬ§ПЦММЁЂБъБДПЦММЮДЙЋПЊХћТЖЦфВЦЮёЪ§ОнаХЯЂЁЃИљОнЙњМЪЪ§ОнЙЋЫОЃЈIDCЃЉЪ§ОнЃЌЙЋЫОЪаГЁЗнЖюдкжаЙњAIЛљДЁЪ§ОнЗўЮёаавЕХХУћЕкЖўЃЌНЯЮЊСьЯШЃЛЙЋЫОдкгЊвЕЪеШыЁЂОЛРћШѓЙцФЃЗНУцЯрБШAppenДцдквЛЖЈСгЪЦЃЌЕЋдкгЏРћФмСІЗНУцЃЌМДзлКЯУЋРћТЪЁЂОЛРћТЪОљгХгкAppenЁЃ
дкзЈРћДЂБИЗНУцЃЌЭЈЙ§ЙЋПЊаХЯЂЧўЕРПЩЛёЯЄЕФAppenЁЂЛлЬ§ПЦММЁЂБъБДПЦММЕФзЈРћДЂБИЪ§СПНЯЩйЃЌЙЋЫОдкзЈРћММЪѕДЂБИЗНУцОпБИУїЯдгХЪЦЁЃдкМЦЫуЛњШэМўжјзїШЈЗНУцЃЌЛлЬ§ПЦМММАЦфзгЙЋЫОЙВгЕгаМЦЫуЛњШэМўжјзїШЈ14ЯюЃЌБъБДПЦМММАЦфзгЙЋЫОЙВгЕгаМЦЫуЛњШэМўжјзїШЈ30ЯюЃЛКЃЬьШ№ЩљМАЦфзгЙЋЫОЙВгЕгаМЦЫуЛњШэМўжјзїШЈ156ЯюЃЌдЖИпгкЙЋПЊаХЯЂПЩВщбЏЕФЛлЬ§ПЦММЁЂБъБДПЦММЕФМЦЫуЛњШэМўжјзїШЈЪ§СПЃЌОпБИвЛЖЈгХЪЦЁЃ
дкгяжж/ЗНбдИВИЧФмСІЗНУцЃЌИљОнAppenЁЂЛлЬ§ПЦММЁЂБъБДПЦММЙйЗНЭјеОЕФаХЯЂЃЌЙЋЫОЕФВњЦЗКЭЗўЮёПЩвдИВИЧГЌЙ§170Иігяжж/ЗНбдЃЌИВИЧЕФгяжж/ЗНбдЪ§СПЩйгкAppenЃЌЕЋЙЋЫОдкздгажЊЪЖВњШЈбЕСЗЪ§ОнВњЦЗЪ§СПЩЯОпБИвЛЖЈгХЪЦЁЃгыЛлЬ§ПЦММЁЂБъБДПЦММЯрБШЃЌЙЋЫОдкВњЦЗКЭЗўЮёИВИЧЕФгяжж/ЗНбдИіЪ§ЁЂздгажЊЪЖВњШЈбЕСЗЪ§ОнВњЦЗЪ§СПЗНУцОљИпгкЙЋПЊаХЯЂПЩВщбЏЕФЛлЬ§ПЦММЁЂБъБДПЦММЕФЯрЙиЪ§СПЃЌОпгаУїЯдЕФгХЪЦЁЃ
3) ГжајШйЛёЖрЯюзЪжЪШйгўЃЌОпгаЛљДЁЪ§ОнЗўЮёаавЕгАЯьСІ
НќФъРДЃЌЙЋЫОЕФКЫаФММЪѕДДаТадЁЂЯШНјадВЛЖЯЕУЕНаавЕЁЂжїЙмВПУХЕФИпЖШШЯПЩЃЌЙЋЫОСЌајЖрФъБЛЦРЮЊЙњМвИпаТММЪѕЦѓвЕЁЂЙњМвЙцЛЎВМОжФкжиЕуШэМўЦѓвЕЃЌВЂШйтпЙЄаХВПЙњМвзЈОЋЬиаТЁАаЁОоШЫЁБЦѓвЕЃЌ2021ФъЛёХњЁАББОЉЪаЦѓвЕММЪѕжааФЁБЃЌВЂвдгХвьБэЯжЛёЦРЙЄаХВПЁАаТвЛДњШЫЙЄжЧФмВњвЕДДаТжиЕуШЮЮёНвАёгХЪЄЕЅЮЛЁБЃЌГфЗжЬхЯжСЫКЃЬьШ№ЩљдкШЫЙЄжЧФмЛљДЁЪ§ОнЗўЮёСьгђзїЮЊаавЕБъИЫКЭСњЭЗЦѓвЕЕФСьЯШзїгУЁЃЙЋЫОЬсЙЉИпжЪСПЁЂИпаЇТЪЁЂИпЫЎзМЕФбЕСЗЪ§ОнВњЦЗМАЗўЮёЃЌзїЮЊШЫЙЄжЧФмВњвЕЗЂеЙЫљБиаыЕФЙиМќвЊЫиЃЌВЙЦыЙЅПЫСЫШЫЙЄжЧФмВњвЕЛљДЁЗЂеЙЦПОБЕФЙиМќвЛЛЗЃЌТњзуСЫбЕСЗЪ§ОнзЪдДЙњВњЛЏзджїДДаТашЧѓЃЌвдзЈвЕадКЭДДаТадЛёЕУСЫаавЕгыжїЙмЛњЙЙИпЖШШЯПЩЃЌВЂдкЭЦЖЏаавЕЗЂеЙЩЯаЮГЩСЫЛ§МЋЕФБъИЫЪОЗЖаЇгІЁЃ
3. БЈИцЦкФкаТММЪѕЁЂаТВњвЕЁЂаТвЕЬЌЁЂаТФЃЪНЕФЗЂеЙЧщПіКЭЮДРДЗЂеЙЧїЪЦ
1) ДѓЙцФЃЁЂИпОЋЖШЁЂИпИДдгЖШашЧѓж№НЅГЃЬЌЛЏЃЌбЕСЗЪ§ОнЩњВњжЧФмЛЏГЩЮЊЗНЯђ
НќФъРДЃЌЫцзХAIгІгУГЁОАШевцЭиПэЁЂШкКЯЁЂЖрдЊЛЏЃЌПЭЛЇдкЪ§ОнЙцФЃЁЂФбЖШЁЂИДдгЖШЗНУцЕФвЊЧѓж№НЅЬЇЩ§ЃЌвджЧФмгявєКЭМЦЫуЛњЪгОѕСьгђЮЊР§ЃЌбЕСЗЪ§ОнашЧѓж№НЅЭиеЙжСИќЖргяжжЁЂИќИДдгГЁОАЁЂИќЖрAIЩшБИЁЂИќЖрвєЩЋРраЭЁЂИќЖрЮЌЕФШЫЯёВЩМЏЁЂИќГЄЮВЕФЮяЬхгАЯёВЩМЏЕШЮЌЖШЃЌетВЛНівЊЧѓЪ§ОнЗўЮёЩЬОпБИИќЗсИЛЕФЪ§ОнВЩЁЂБъОбщЃЌВЂдкЪ§ОнЩњВњЙ§ГЬжаВЛЖЯв§ШыЫуЗЈЁЂЬсЩ§ЦНЬЈФмСІЃЌвдГжајЕќДњЕФжЧФмЛЏШЫЛњазїФЃЪНРДВЛЖЯЬсИпЪ§ОнДІРэжЪСПКЭаЇТЪЁЂНЕЕЭГЩБОЃЌЧ§ЖЏаавЕЯђбЕСЗЪ§ОнЩњВњжЧФмЛЏЕФЗНЯђбнНјЁЃ
2) гябд/гяжжЖрдЊЛЏЪ§ОнашЧѓВЛЖЯХЪЩ§
ЫцзХЙњМвЁАвЛДјвЛТЗЁБеНТдЕФНјвЛВНЩюШыЭЦНјЃЌЮвЙњЦѓвЕГіКЃВМОждіЖрЃЛЭЌЪБЃЌЙњЭтжїСїЕФбЕСЗЪ§ОнашЧѓЦѓвЕДѓЖрдчвбЪЕЯжШЋЧђВМОжЃЌВЂГЪЯжВЛЖЯРЉГфЁЂЯИЛЏЧјгђЭиеЙВпТдЕФЧїЪЦЁЃдкДЫБГОАЯТЃЌЪаГЁЖдЖргябдбЕСЗЪ§ОнЕФашЧѓгРДаТвЛТждіГЄЃЌГ§жаЁЂгЂЁЂЗЈЁЂЕТЁЂвтЁЂЮїЁЂШеЁЂКЋЕШГЃМћгяжжЭтЃЌдЄМЦПЭЛЇШКЬхЛЙНЋдкжюШчЖЋФЯбЧЁЂвЛДјвЛТЗбиЯпЙњМвЕиЧјЕФКБМћаЁгяжжЃЈгШЦфЪЧбЧжоаЁгяжжЃЉЗНЯђВњЩњаТЕФдіСПашЧѓЃЌжЛгаФЧаЉдкЖргябд/гяжжЛљДЁбаОПЗНУцГжајЭЖШыЁЂгЕгавЛЖЈЛ§Рл
ЕФЪ§ОнЗўЮёЩЬЗНФмзЅзЁДЫЦѕЛњЁЂТњзуПЭЛЇашЧѓЁЃ
3) жЧФмМнЪЛСьгђв§СьЪ§ОнашЧѓЭиеЙжСИќЖрДЙжБГЁОАЃЌЖдаавЕЬсГіИќИпвЊЧѓЫцзХAIВњвЕТфЕиГЩЮЊжїа§ТЩЃЌЪ§ОнВЩЁЂБъЗўЮёашТњзуЕФAIгІгУГЁОАБШвдЭљУїЯдИќМгЙуЗКЃЌМгжЎЪ§ОнжЪСПОіЖЈAIЯЕЭГдЄВтЕФзМШЗЖШЃЌаавЕгУЛЇЖдЪ§ОнЗўЮёЩЬдкЬиЖЈДЙжБГЁОАЯТзЈвЕадвЊЧѓе§дкЬсИпЃЌДЙжБГЁОАЕФЖЈжЦЛЏбЕСЗЪ§ОнашЧѓНЋГЩЮЊжїСїЁЃ
дкЯИЗжаавЕМАГЁОАЫљОпБИЕФзЈвЕжЊЪЖЁЂЗўЮёОбщвдМАзМШызЪжЪНЋГЩЮЊКтСПвЛМвЪ§ОнЗўЮёЩЬЪЧЗёОпБИДЙжБСьгђЪ§ОнЗўЮёФмСІЕФживЊПМСПвђЫиЁЃЕБЧАЃЌвджЧФмМнЪЛЮЊДњБэЕФДЙжБСьгђвбПЊЪМЪЭЗХДѓЙцФЃбЕСЗЪ§ОнашЧѓЃЌаавЕПЭЛЇИќМгашвЊЕУЕНШЋеЛЪНЕФБеЛЗЪ§ОнНтОіЗНАИЃЌвдТњзужЧФмМнЪЛвЕЮёЕФЪ§ОнДІРэСПИќДѓЁЂЪ§ОнДІРэашЧѓЕФЕќДњЦЕДЮИќИпЁЂКЯЙцвЊЧѓИќИпЕШЬиЕуЃЌетОЭвЊЧѓЪ§ОнЗўЮёЩЬдкзЈвЕФмСІЃЈАќРЈЕЋВЛЯогкЖдгкНЛЭЈГЁОАЁЂГЕСОДЋИаЦїЕШвЊЫиЕФзлКЯРэНтКЭЪЕЪЉФмСІЃЉЁЂзлКЯФмСІЃЈАќРЈЕЋВЛЯогкЪ§ОнДІРэЦНЬЈФмСІЁЂжЪСПЙмПиФмСІЁЂашЧѓЖдНгФмСІЁЂЯюФПЯьгІФмСІЁЂЙЉгІСДзЪдДЙмРэФмСІЕШЃЉЁЂзМШызЪжЪЕШЗНУцЭЌЪБТњзуДяЕННЯИпЫЎзМЁЃ
4) Ъ§ОнАВШЋгывўЫНБЃЛЄвЊЧѓПьЫйЬсЩ§ЃЌПМбщЪ§ОнЗўЮёЩЬКЯЙцЗўЮёФмСІ
НќФъРДЃЌЁЖЪ§ОнАВШЋЗЈЁЗЁЂЁЖИіШЫаХЯЂБЃЛЄЗЈЁЗЁЂЁЖЦћГЕЪ§ОнАВШЋЙмРэШєИЩЙцЖЈЃЈЪдааЃЉЁЗЕШжїСїЗЈТЩЗЈЙцвбОПьЫйТфЕиЪЕЪЉЃЌаавЕПЩвдЧхЮњЕиИаЪмЕНЙњМвдкетЗНУцЕФЗЈТЩЛЗОГдкПьЫйЧїбЯЃЌЪ§ОнАВШЋЯрЙиЗЈТЩЬхЯЕЕФЭъЩЦЖдбЕСЗЪ§ОнВњвЕЕФНЁПЕЗЂеЙНЋВњЩњЩюдЖЕФгАЯьЃЌгаРћгкЙцЗЖаавЕааЮЊЁЂжЮРэаавЕТвЯѓЃЌЬсИпаавЕУХМїЃЌЮЊЪЕЯжаавЕПЩГжајСМадЗЂеЙДДдьНЁПЕЛЗОГЁЃ
дкДЫБГОАЯТЃЌЪ§ОнАВШЋЁЂвўЫНБЃЛЄНЋГЩЮЊаавЕгУЛЇбЁдёЪ§ОнВЩБъЗўЮёЪБЕФживЊПМСПвђЫиЃЌЩѕжСвЛаЉДѓаЭашЧѓЗНдкхрбЁЪ§ОнЗўЮёЩЬЪБвбНЋДЫвђЫиЬсЩ§жСживЊМЖБ№ЁЃвђДЫЃЌЪ§ОнЗўЮёЩЬдкДЫЗНУцаыНєИњЙњМвЗЈТЩЗЈЙцвЊЧѓЕФбнБфЃЌЯргІЕїећЁЂЩ§МЖЯжаавЕЮёПЊеЙЗНЪНЁЂЪ§ОнАВШЋЙмРэЬхЯЕЃЌМАЪБЛёШЁКЯЙцзЪжЪЃЈАќРЈЕЋВЛЯогкаХЯЂАВШЋЙмРэЬхЯЕШЯжЄЁЂвўЫНаХЯЂЙмРэЬхЯЕШЯжЄЁЂЭјТчАВШЋЕШМЖБЃЛЄВтЦРЕШЃЉЃЌЧаЪЕЬсЩ§здЩэЪ§ОнАВШЋгыКЯЙцФмСІЃЌШЗБЃвЕЮёЪМжедкНЁПЕЁЂКЯЙцЕФЛЗОГЯТПЊеЙЃЌВЂНЋздЩэдкетЗНУцЕФЛ§РлзЊЛЏЮЊОКељгХЪЦЁЃ
3 ЙЋЫОжївЊЛсМЦЪ§ОнКЭВЦЮёжИБъ
3.1 Нќ3ФъЕФжївЊЛсМЦЪ§ОнКЭВЦЮёжИБъ
ЕЅЮЛЃКдЊ БвжжЃКШЫУёБв
| 2021Фъ | 2020Фъ | БОФъБШЩЯФъ діМѕ(%) | 2019Фъ | |
| змзЪВњ | 840,663,396.09 | 477,350,038.99 | 76.11 | 404,539,351.88 |
| ЙщЪєгкЩЯЪаЙЋЫОЙЩ | 805,908,403.05 | 437,956,372.58 | 84.02 | 355,951,438.36 |
| ЖЋЕФОЛзЪВњ | ||||
| гЊвЕЪеШы | 206,476,533.04 | 233,373,953.01 | -11.53 | 237,558,118.15 |
| ЙщЪєгкЩЯЪаЙЋЫОЙЩЖЋЕФОЛРћШѓ | 31,605,431.79 | 82,081,021.91 | -61.49 | 81,586,824.49 |
| ЙщЪєгкЩЯЪаЙЋЫОЙЩЖЋЕФПлГ§ЗЧОГЃадЫ№вцЕФОЛРћШѓ | 21,067,433.20 | 73,015,355.36 | -71.15 | 76,246,636.59 |
| ОгЊЛюЖЏВњЩњЕФЯжН№СїСПОЛЖю | -15,548,319.63 | 51,176,659.14 | -130.38 | 83,363,303.85 |
| МгШЈЦНОљОЛзЪВњЪевцТЪЃЈ%ЃЉ | 5.59 | 20.68 | МѕЩй15.09ИіАйЗжЕу | 39.78 |
| ЛљБОУПЙЩЪевцЃЈдЊЃЏЙЩЃЉ | 0.89 | 2.56 | -65.23 | 2.72 |
| ЯЁЪЭУПЙЩЪевцЃЈдЊЃЏЙЩЃЉ | 0.89 | 2.56 | -65.23 | 2.72 |
| баЗЂЭЖШыеМгЊвЕЪеШыЕФБШР§ЃЈ%ЃЉ | 29.31 | 18.64 | діМг10.67ИіАйЗжЕу | 17.55 |
3.2 БЈИцЦкЗжМОЖШЕФжївЊЛсМЦЪ§Он
ЕЅЮЛЃКдЊ БвжжЃКШЫУёБв
| ЕквЛМОЖШ ЃЈ1-3дТЗнЃЉ | ЕкЖўМОЖШ ЃЈ4-6дТЗнЃЉ | ЕкШ§МОЖШ ЃЈ7-9дТЗнЃЉ | ЕкЫФМОЖШ ЃЈ10-12дТЗнЃЉ | |
| гЊвЕЪеШы | 44,238,877.46 | 61,762,722.07 | 24,774,663.82 | 75,700,269.69 |
| ЙщЪєгкЩЯЪаЙЋЫОЙЩЖЋЕФОЛРћШѓ | 16,341,743.76 | 21,473,377.86 | -12,156,689.84 | 5,947,000.01 |
| ЙщЪєгкЩЯЪаЙЋЫОЙЩЖЋЕФПлГ§ЗЧОГЃадЫ№вцКѓЕФОЛРћШѓ | 14,324,978.64 | 19,365,100.35 | -14,490,933.13 | 1,868,287.34 |
| ОгЊЛюЖЏВњЩњЕФЯжН№СїСПОЛЖю | 18,456,157.25 | -8,507,682.68 | -23,550,934.24 | -1,945,859.96 |
МОЖШЪ§ОнгывбХћТЖЖЈЦкБЈИцЪ§ОнВювьЫЕУї
ЁѕЪЪгУ ЁЬВЛЪЪгУ
4 ЙЩЖЋЧщПі
4.1 ЦеЭЈЙЩЙЩЖЋзмЪ§ЁЂБэОіШЈЛжИДЕФгХЯШЙЩЙЩЖЋзмЪ§КЭГжгаЬиБ№БэОіШЈЙЩЗнЕФЙЩЖЋзмЪ§МАЧА 10УћЙЩЖЋЧщПі
ЕЅЮЛ: ЙЩ
| НижСБЈИцЦкФЉЦеЭЈЙЩЙЩЖЋзмЪ§(ЛЇ) | 4,825 | ||||||||
| ФъЖШБЈИцХћТЖШеЧАЩЯвЛдТФЉЕФЦеЭЈЙЩЙЩЖЋзмЪ§(ЛЇ) | 4,875 | ||||||||
| НижСБЈИцЦкФЉБэОіШЈЛжИДЕФгХЯШЙЩЙЩЖЋзмЪ§ЃЈЛЇЃЉ | 0 | ||||||||
| ФъЖШБЈИцХћТЖШеЧАЩЯвЛдТФЉБэОіШЈЛжИДЕФгХЯШЙЩЙЩЖЋзмЪ§ЃЈЛЇЃЉ | 0 | ||||||||
| НижСБЈИцЦкФЉГжгаЬиБ№БэОіШЈЙЩЗнЕФЙЩЖЋзмЪ§ЃЈЛЇЃЉ | 0 | ||||||||
| ФъЖШБЈИцХћТЖШеЧАЩЯвЛдТФЉГжгаЬиБ№БэОіШЈЙЩЗнЕФЙЩЖЋзмЪ§ЃЈЛЇЃЉ | 0 | ||||||||
| ЧАЪЎУћЙЩЖЋГжЙЩЧщПі | |||||||||
| ЙЩЖЋУћГЦ ЃЈШЋГЦЃЉ | БЈИцЦкФкдіМѕ | ЦкФЉГжЙЩЪ§СП | БШР§(%) | ГжгагаЯоЪлЬѕМўЙЩЗнЪ§СП | АќКЌзЊШкЭЈНшГіЙЩЗнЕФЯоЪлЙЩЗнЪ§СП | жЪбКЁЂБъМЧЛђЖГНсЧщПі | ЙЩЖЋ аджЪ | ||
| ЙЩЗн зДЬЌ | Ъ§СП | ||||||||
| КиСе | 0 | 8,669,725 | 20.26 | 8,669,725 | 8,669,725 | Юо | ОГФкздШЛШЫ | ||
| ББОЉжаШ№АВЭЖзЪжааФЃЈгаЯоКЯЛяЃЉ | 0 | 4,954,128 | 11.58 | 4,954,128 | 4,954,128 | Юо | ЦфЫћ | ||
| жавЦЭЖзЪПиЙЩгаЯод№ШЮЙЋЫО | 0 | 3,855,000 | 9.01 | 3,855,000 | 3,855,000 | Юо | ЙњгаЗЈШЫ | ||
| ЬЦЕгЗЩ | 0 | 3,577,982 | 8.36 | 3,577,982 | 3,577,982 | Юо | ОГФкздШЛШЫ | ||
| ББОЉЧхЕТЭЖзЪжааФЃЈгаЯоКЯЛяЃЉ | 0 | 2,545,463 | 5.95 | 2,545,463 | 2,545,463 | Юо | ЦфЫћ | ||
| ЩЯКЃЗсчўЭЖзЪКЯЛяЦѓвЕЃЈгаЯоКЯЛяЃЉ | 0 | 1,880,374 | 4.39 | 1,880,374 | 1,880,374 | Юо | ЦфЫћ | ||
| ББОЉжаШ№СЂЭЖзЪжааФЃЈгаЯоКЯЛяЃЉ | 0 | 1,871,560 | 4.37 | 1,871,560 | 1,871,560 | Юо | ЦфЫћ | ||
| ЩЯКЃаЫИЛДДвЕЭЖзЪЙмРэжааФЃЈгаЯоКЯЛяЃЉ | 0 | 1,323,112 | 3.09 | 1,323,112 | 1,323,112 | Юо | ЦфЫћ | ||
| жаЙњЛЅСЊЭјЭЖзЪЛљН№ЙмРэгаЯоЙЋЫОЃжаЙњЛЅСЊЭјЭЖзЪЛљН№ЃЈгаЯоКЯЛяЃЉ | 0 | 1,290,000 | 3.01 | 1,290,000 | 1,290,000 | Юо | ЦфЫћ | ||
| ЛЊЬЉжЄШЏзЪЙмЃеаЩЬвјааЃЛЊЬЉКЃЬьШ№ЩљМвдА1КХПЦДДАхдБЙЄГжЙЩМЏКЯзЪВњЙмРэМЦЛЎ | 0 | 1,070,000 | 2.50 | 1,070,000 | 1,070,000 | Юо | ЦфЫћ | ||
| ЩЯЪіЙЩЖЋЙиСЊЙиЯЕЛђвЛжТааЖЏЕФЫЕУї | ЩЯЪіЙЩЖЋжаЃЌ1ЁЂЙЋЫОПиЙЩЙЩЖЋЁЂЪЕМЪПижЦШЫКиСеГжга100%ЙЩШЈЕФББОЉДДЪРСЊКЯЭЖзЪЙмРэгаЯоЙЋЫОЮЊББОЉжаШ№АВЭЖзЪжааФЃЈгаЯоКЯЛяЃЉЕФЦеЭЈКЯЛяШЫЁЂжДааЪТЮёКЯЛяШЫЃЌВЂГжгаББОЉжаШ№АВЭЖзЪжааФЃЈгаЯоКЯЛяЃЉ36.67%ЕФГізЪЃЌКиСеЮЊББОЉжаШ№СЂЭЖзЪжааФЃЈгаЯоКЯЛяЃЉЕФгаЯоКЯЛяШЫЃЌГжгаББОЉжаШ№СЂЭЖзЪжааФЃЈгаЯоКЯЛяЃЉ5.88%ЕФГізЪЃЛ2ЁЂЬЦЕгЗЩГжга50%ЙЩШЈЕФББОЉДДЛлПЦШ№ЭЖзЪЙмРэгаЯоЙЋЫОЮЊББОЉжаШ№СЂЭЖзЪжааФЃЈгаЯоКЯЛяЃЉЕФЦеЭЈКЯЛяШЫЁЂжДааЪТЮёКЯЛяШЫЃЌВЂГжгаББОЉжаШ№СЂЭЖзЪжааФЃЈгаЯоКЯЛяЃЉ29.41%ЕФГізЪЃЌЬЦЕгЗЩЮЊББОЉжаШ№СЂЭЖзЪжааФЃЈгаЯоКЯЛяЃЉЕФЮЏХЩДњБэЃЛ3ЁЂББОЉЧхЕТЭЖзЪжааФЃЈгаЯоКЯЛяЃЉЦеЭЈКЯЛяШЫЁЂжДааЪТЮёКЯЛяШЫжгЩНМАЦфХфХМжОХєЗжБ№ГжгаББОЉЧхЕТЭЖзЪжааФЃЈгаЯоКЯЛяЃЉ8.76%ЁЂ4.31%ЕФГізЪЃЌжОХєЭЌЪБГжгаББОЉжаШ№СЂЭЖзЪжааФЃЈгаЯоКЯЛяЃЉЦеЭЈКЯЛяШЫЁЂжДааЪТЮёКЯЛяШЫББОЉДДЛлПЦШ№ЭЖзЪЙмРэгаЯоЙЋЫО50%ЕФЙЩШЈЃЛ4ЁЂжавЦЭЖзЪПиЙЩгаЯод№ШЮЙЋЫОЕФМфНгПиЙЩЙЩЖЋжаЙњвЦЖЏЭЈаХМЏЭХгаЯоЙЋЫОЮЊжаЙњЛЅСЊЭјЭЖзЪЛљН№ЃЈгаЯоКЯЛяЃЉЕФгаЯоКЯЛяШЫЃЌГжгажаЙњЛЅСЊЭјЭЖзЪЛљН№ЃЈгаЯоКЯЛяЃЉ9.97%ЕФГізЪЃЌжаЙњвЦЖЏЭЈаХМЏЭХгаЯоЙЋЫОЕФШЋзЪзгЙЋЫОжавЦзЪБОПиЙЩгаЯод№ШЮЙЋЫОГжгажаЙњЛЅСЊЭјЭЖзЪЛљН№ЃЈгаЯоКЯЛяЃЉЦеЭЈКЯЛяШЫЁЂжДааЪТЮёКЯЛяШЫжаЙњЛЅСЊЭјЭЖзЪЛљН№ЙмРэЙЋЫОЃЈГжгажаЙњЛЅСЊЭјЭЖзЪЛљН№ЃЈгаЯоКЯЛяЃЉ0.33%ЕФГізЪЃЉ16.36%ЕФЙЩШЈЃЛ5ЁЂЛЊЬЉжЄШЏзЪЙмЃеаЩЬвјааЃЛЊЬЉКЃЬьШ№ЩљМвдА1КХПЦДДАхдБЙЄГжЙЩМЏКЯзЪВњЙмРэМЦЛЎЮЊЙЋЫОВПЗжИпМЖЙмРэШЫдБМАКЫаФдБЙЄВЮгыеНТдХфЪлЫљГЩСЂЕФзЈЯюзЪЙмМЦЛЎЁЃГ§ДЫжЎЭтЃЌЙЋЫОЮДжЊЩЯЪіЦфЫћЙЩЖЋжЎМфЪЧЗёДцдкЙиСЊЙиЯЕЛђЪєгквЛжТааЖЏШЫЁЃ | ||||||||
| БэОіШЈЛжИДЕФгХЯШЙЩЙЩЖЋМАГжЙЩЪ§СПЕФЫЕУї | Юо |
ДцЭаЦОжЄГжгаШЫЧщПі
ЁѕЪЪгУ ЁЬВЛЪЪгУ
НижСБЈИцЦкФЉБэОіШЈЪ§СПЧАЪЎУћЙЩЖЋЧщПіБэ
ЁѕЪЪгУ ЁЬВЛЪЪгУ
4.2 ЙЋЫОгыПиЙЩЙЩЖЋжЎМфЕФВњШЈМАПижЦЙиЯЕЕФЗНПђЭМ
ЁЬЪЪгУ ЁѕВЛЪЪгУ
4.3 ЙЋЫОгыЪЕМЪПижЦШЫжЎМфЕФВњШЈМАПижЦЙиЯЕЕФЗНПђЭМ
ЁЬЪЪгУ ЁѕВЛЪЪгУ
4.4 БЈИцЦкФЉЙЋЫОгХЯШЙЩЙЩЖЋзмЪ§МАЧА10 УћЙЩЖЋЧщПі
ЁѕЪЪгУ ЁЬВЛЪЪгУ
5 ЙЋЫОеЎШЏЧщПі
ЁѕЪЪгУ ЁЬВЛЪЪгУ
ЕкШ§Нк живЊЪТЯю
1 ЙЋЫОгІЕБИљОнживЊадддђЃЌХћТЖБЈИцЦкФкЙЋЫООгЊЧщПіЕФжиДѓБфЛЏЃЌвдМАБЈИцЦкФкЗЂЩњЕФЖдЙЋЫООгЊЧщПігажиДѓгАЯьКЭдЄМЦЮДРДЛсгажиДѓгАЯьЕФЪТЯюЁЃ
БЈИцЦкФкЃЌЙЋЫОЪЕЯжгЊвЕЪеШы20,647.65ЭђдЊЃЌЪЕЯжЙщЪєгкФИЙЋЫОЫљгаепЕФОЛРћШѓ3,160.54ЭђдЊЃЌЪЕЯжЙщЪєгкФИЙЋЫОЫљгаепЕФПлГ§ЗЧОГЃадЫ№вцЕФОЛРћШѓ2,106.74ЭђдЊЃЌЗжБ№НЯЩЯФъЭЌЦкМѕЩй
11.53%ЁЂ61.49%ЁЂ71.15%ЁЃНижСБЈИцЦкФЉЃЌЙЋЫОзмзЪВњЮЊ84,066.34ЭђдЊЃЌЙщЪєгкФИЙЋЫОЕФЫљгаепШЈвцЮЊ80,590.84ЭђдЊЃЌЗжБ№НЯЩЯФъФЉдіМг76.11%КЭ84.02%ЁЃ
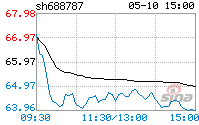
2 ЙЋЫОФъЖШБЈИцХћТЖКѓДцдкЭЫЪаЗчЯеОЏЪОЛђжежЙЩЯЪаЧщаЮЕФЃЌгІЕБХћТЖЕМжТЭЫЪаЗчЯеОЏЪОЛђжежЙЩЯЪаЧщаЮЕФдвђЁЃ
ЁѕЪЪгУ ЁЬВЛЪЪгУ